Oh j’ai appris un truc ![]()
1 « J'aime »
Tu l’intègres dans quelle ligne de ton Json ?
Question bête je te l’accorde
T’en fais pas David, il n’y a pas de question bête, que des réponses stupides ![]()
Il faut que tu ailles dans le menu, puis « Edit metadata », comme suit:
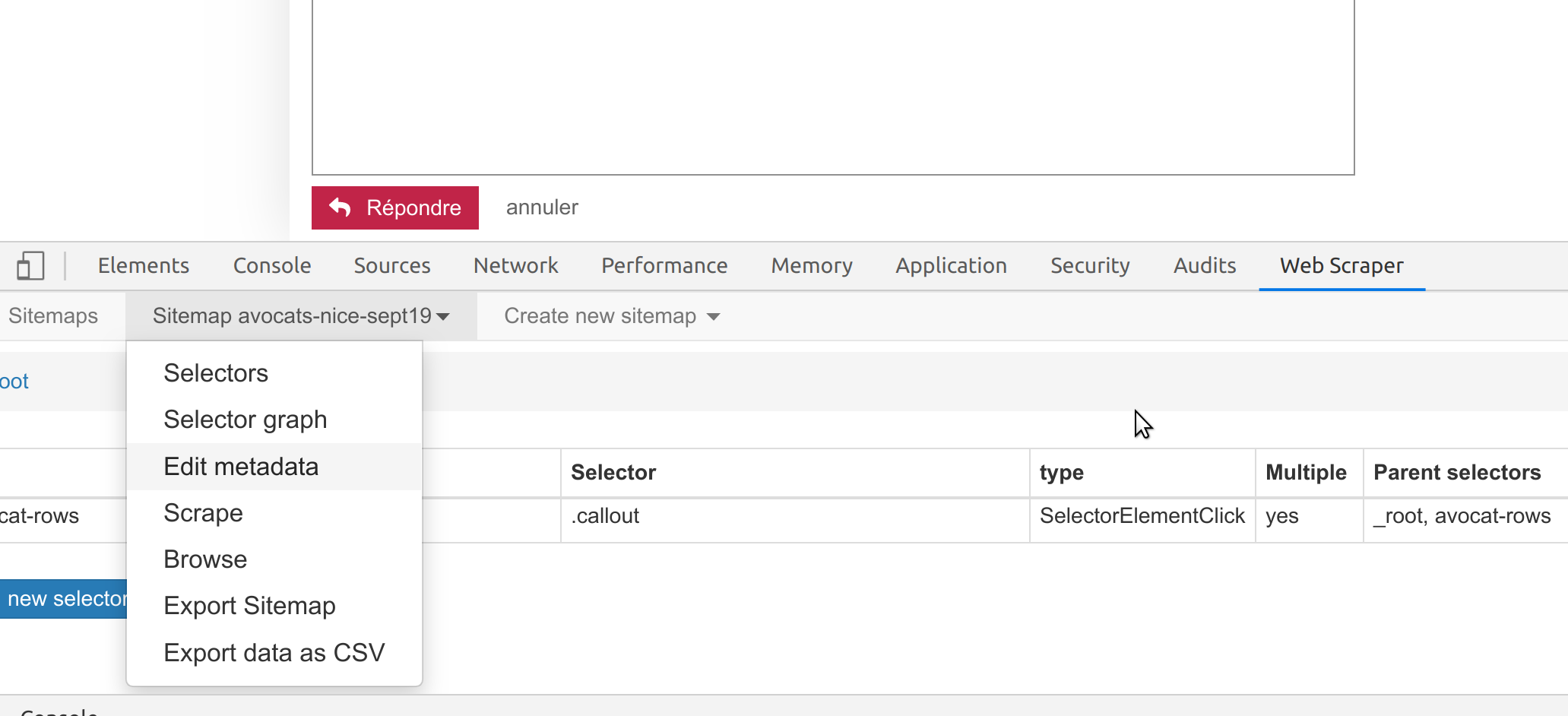
Le but étant d’éditer la « Start URL »:
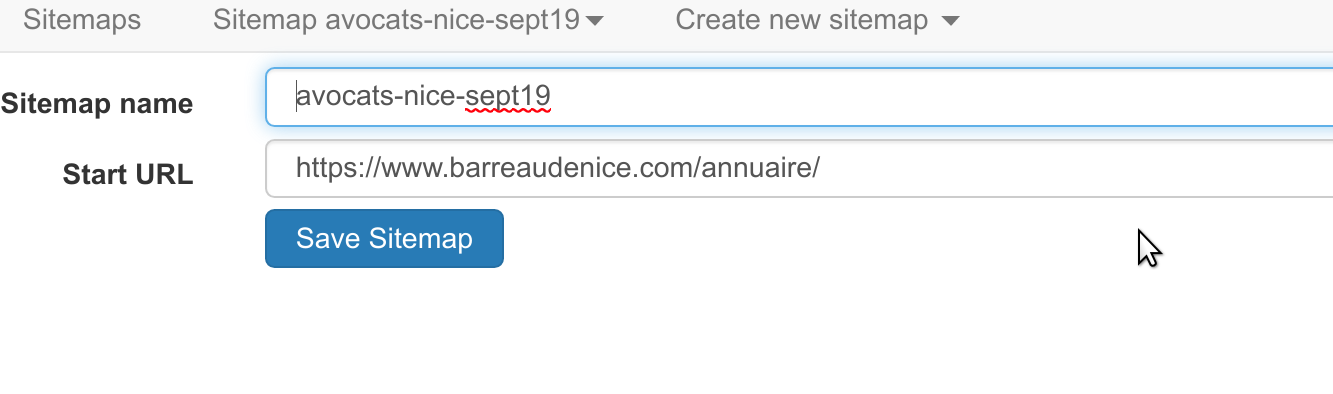
Donc j’ai re-essayé la manip en ajoutant en fin d’url le " &page=[1-100] " dans la metadata
Ça n’a pas été concluant.
Je pense que c’est une histoire de pagination, à la rigueur je peux partir de ton json pour ensuite réaliser une pagination à la main avec les selectors non?
Là comme ça je ne vois pas trop le problème que tu rencontres, sachant que la méthode des starts urls avec variation du numéro de la page courante via la syntaxe paramètre=[1-N] fonctionne bien d’habitude.
Peux tu partager ton sitemap JSON ici ? Via la fonctionnalité de texte préformaté, et j’y jettes un oeil ![]()
{"_id":"sitemapiledefrance","startUrl":["https://www.pagesjaunes.fr/recherche/region/ile-de-france/expert-comptable"],"selectors":[{"id":"article","type":"SelectorElement","parentSelectors":["_root"],"selector":"article","multiple":true,"delay":0},{"id":"titre","type":"SelectorText","parentSelectors":["article"],"selector":"a.denomination-links","multiple":false,"regex":"","delay":0},{"id":"adresse","type":"SelectorText","parentSelectors":["article"],"selector":"a.adresse","multiple":false,"regex":"","delay":0},{"id":"categorie","type":"SelectorText","parentSelectors":["article"],"selector":"a.activites","multiple":false,"regex":"","delay":0},{"id":"prestations","type":"SelectorText","parentSelectors":["article"],"selector":"p:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"autre","type":"SelectorText","parentSelectors":["article"],"selector":"p:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"link","type":"SelectorLink","parentSelectors":["article"],"selector":"a.denomination-links","multiple":false,"delay":0},{"id":"tel","type":"SelectorText","parentSelectors":["link"],"selector":"span.coord-numero.noTrad","multiple":false,"regex":"","delay":0},{"id":"images","type":"SelectorImage","parentSelectors":["link"],"selector":".photo img","multiple":true,"delay":0},{"id":"website","type":"SelectorText","parentSelectors":["link"],"selector":".teaser-item.pj-lb span.value","multiple":false,"regex":"","delay":0}]}
En l’occurence, pour ma recherche : Ile de france (expert comptable) la commande serait &page=[1-100] car il y a 100 pages sur cette requête
Lorsque tu cliques sur le bouton « Page 2 », tu peux voir que l’URL de départ change un peu. Et il faut que celle-ci devienne ton nouveau point de départ, de telle sorte que ta start URL devienne:
https://www.pagesjaunes.fr/annuaire/chercherlespros?quoiqui=expert%20comptable&ou=ile-de-france&proximite=0&quoiQuiInterprete=expert%20comptable&contexte=MR4h7VwtwblW3Q1pk2Sduw%3D%3D&idOu=R11&page=[1-100]
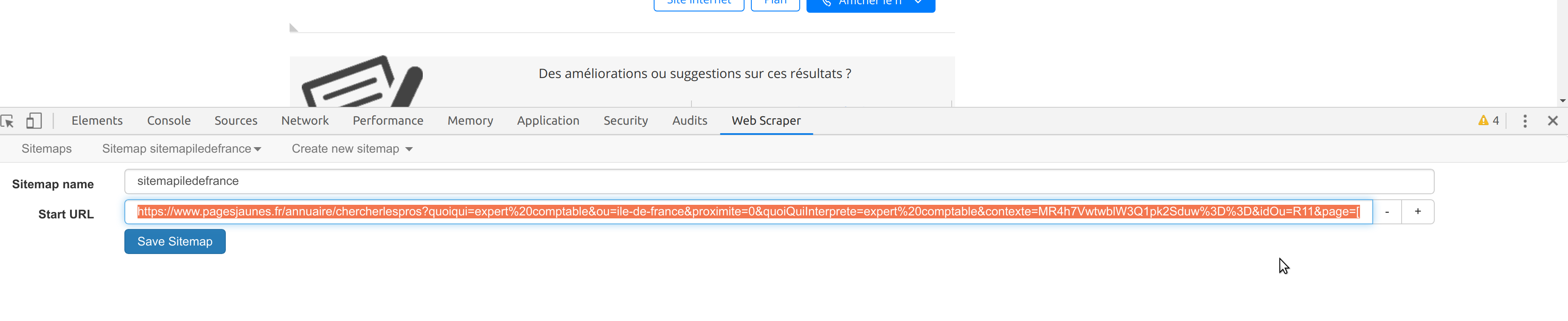
Par contre attention au paramètre « contexte » qu’on voit dans l’URL, apparemment il est généré dynamiquement à chaque nouvelle recherche sur le site, je suppose qu’il doit avoir une durée de validité dans le temps, et que si tu reviens X minutes ou heures plus tard, l’ordre des recherches aura changé…
Hello, à tous, super post ![]()
Concernant les emails des pages jaunes, quelqu’un a une solution ?
Les emails étaient dispo par un temps, il étaient encodés en base64 dans un attribut d’une des balises HTML de la page ciblée, mais à priori ce n’est plus le cas… ![]()
si tu es pas trop technique tu as annucapt un peu plus avancer zennoposter et avancé scrapy
zennoposter reste mon préféré ![]()
Hello ! lorsque je copie ton code dans import sitemap, ca me dit invalid json. Du coup j’ai juste retirer les ’ au début et à la fin. Malheuresement quand je lance le scrap, je n’ai aucune data ![]() Tu as une idée ? Je n’ai absolument rien changé ton code.
Tu as une idée ? Je n’ai absolument rien changé ton code.