J’utilise Octoparse mais malheureusement je n’y arrive pas. Le problème que je rencontre est le suivant :
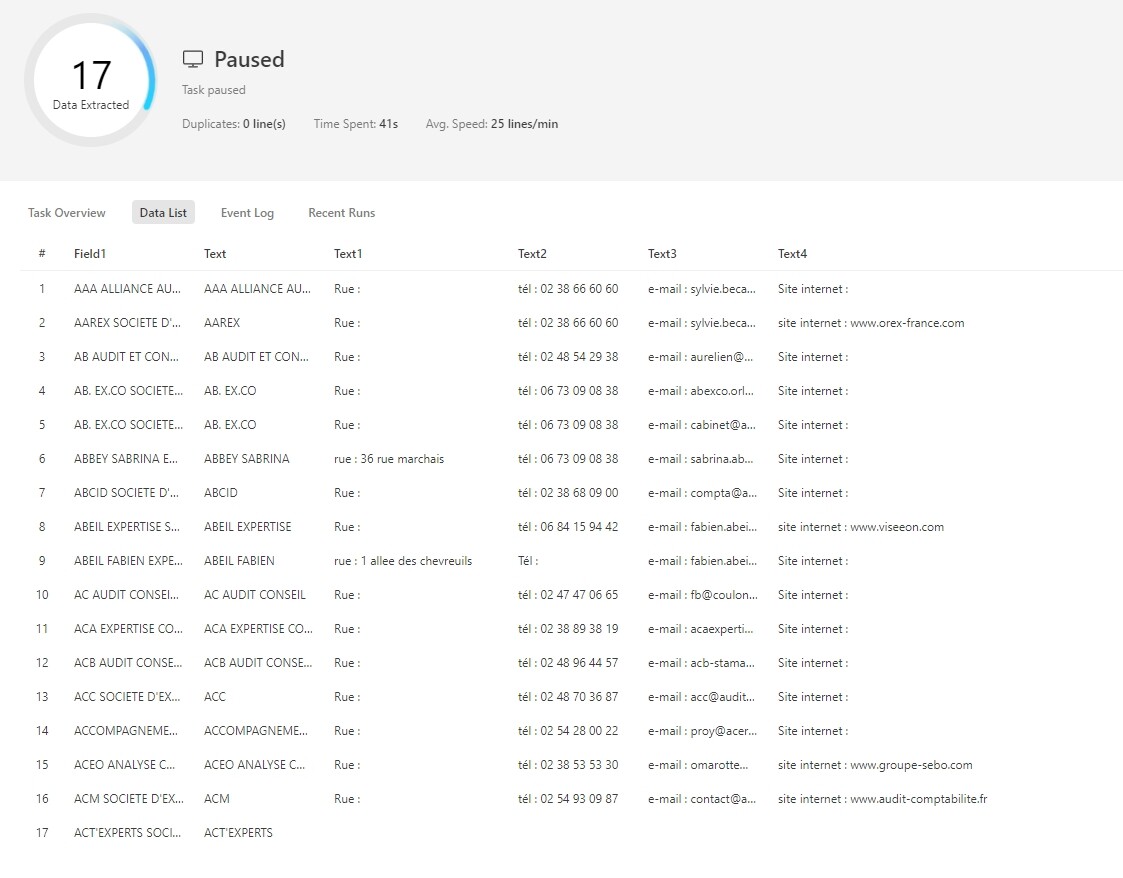
Je n’arrive pas à automatiser l’ouverture d’une zone dépliable et à extraire les données. Et ça pour 1000 zones. Je vous laisse regarder comment est fait le site vous allez mieux comprendre.
Si quelqu’un à une solution je veux bien. Un grand merci à vous
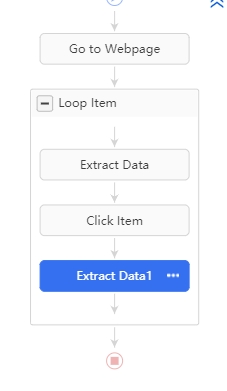
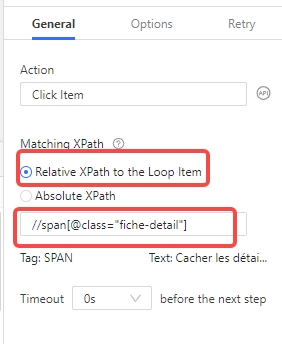
cliquer sur le bouton « Afficher les détails ». Il faut préciser le XPath de ce bouton, c’est //span[@class=« fiche-detail »]
sélectionner et extraire les données. L’essentiel de cette étape consiste également à corriger le XPath ( généralement, si vous n’arrivez pas à collecter correctement les données, c’est souvent à cause de XPath).
Rue : //span[@class=« fiche-info rue »]
Tél : //span[@class=« fiche-info tel »]
e-mail : //span[@class=« fiche-info email »]
Site : //span[@class=« fiche-info site »]
J’espère que ma réponse peut vous aider.
Pour finir, le Xpath semble très important pour octoparse. Je l’impression de corriger pas mal de xpath. mais à vrai dire, cela m’apporte souvent un sens de satisfaction hhahahha
Si vous voulez comprendre davantage, il y a tutoriel et leur support est excellent.