Bonjour à tous,
Je souhaite lancer une campagne publicitaire pour notre nouveau site internet, pour cela j’ai penser à scraper les site annuaire pour les crèches et collectivités.
Ma première cible serait:
l’avantage: url des crèche est un numéro donc facile a trouver meme si cela est séquentiel
exemple: ACCUEIL FAMILIAL à Nantes (44000)
Je souhaite apprendre le scraping et je suis entrain de tester avec import.io après un echec avec webscraper.
Avez vous une solution pour scraper ou récupérer efficacement des email sur ce genre de site internet ?
Je serais prêt a payer une formation ou des tutoriels car cela pourrait mettre d’une grande aide dans les mois futur
Merci beaucoup pour votre aide, votre partage de savoir et de vos connaissance mise à disposition de tous ! have fun
Si tu es en mesure d’obtenir la liste complète des URLs des pages crèches, alors tu peux utiliser cette liste (en CSV par exemple) pour l’injecter en tant qu’input dans Dataminer
Ou alors, créer une fausse page HTML contenant toutes ces URLs sous forme de liens <a href="https://www.journaldesfemmes.fr/maman/creches/micro-creche-les-souris-vertes-de-sainte-neomaye/creche-7850">MICRO-CRÈCHE LES SOURIS VERTES DE SAINTE NEOMAYE</a> , et à partir de cette page HTML, créér un scénario avec Webscraper, qui ira cliquer sur chacun des liens pour extraire les infos depuis chaque page crèche.
oui sauf que entre temps je viens de voir que c’est plus complex que prévus… en effet parfois ca change et j’ai pu récupérer que 300 mail comme ca et en plus les mails sont en doublon xD
je partage ma découverte: site:www.site.fr/xxx/xx « xxx""@orange.fr »
par exemple permet sur google de découvrir tout les mail en orange.fr pour ce qui est de faire du volume avec ceci…
A ce stade, si tu veux récupérer l’intégralité des données, soit il faudrait maîtriser à 100% WebScraper, soit savoir coder pour faire ton propre robot d’extract…
Il te reste à te poser la question: veux tu passer beaucoup de temps là dessus, ou bien déléguer cette tâche, car à priori ce n’est pas sur l’automatisation ou sur la partie extraction que tu vas apporter de la plus-value, tu risques d’y passer du temps, temps que tu pourrais mettre au profit des sujets que tu maitrises vraiment et où tu apportes de la valeur ajoutée.
De manière générale, je code tous mes propres scripts d’extraction. Je pêche clairement coté tools déjà existants, ce n’est pas mon data.
Je saurais le faire avec un outil comme Dataminer, mais il limite aux 500 premières pages (gratuites), au delà, il faut payer.
J’ai bien un framework maison qui fait le job, mais je préfére laisser la place aux plus smarts qui connaissent l’outil déjà existant qui ferait le job pour rien, si ça existe
Salut @Papouille,
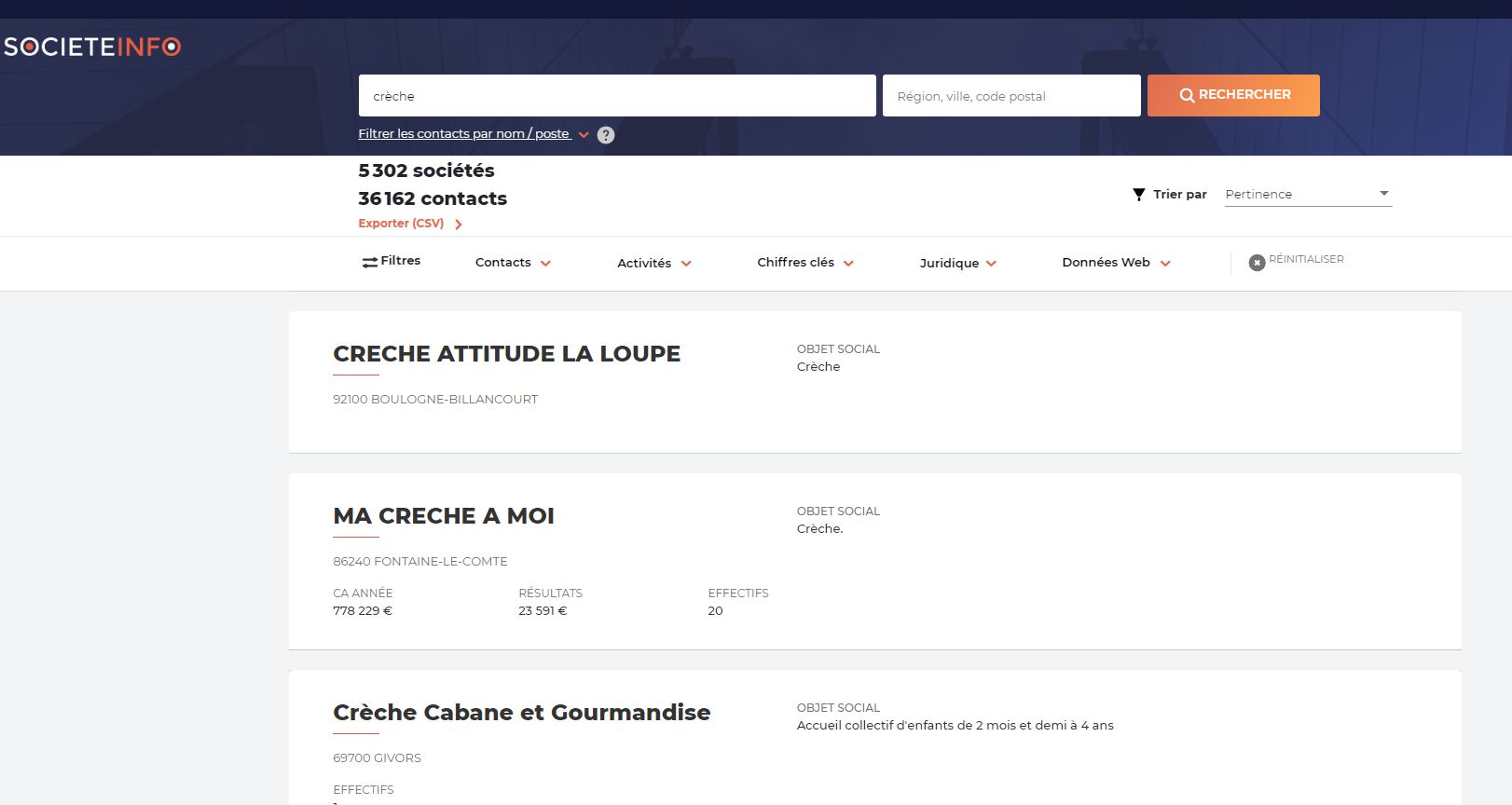
Sans vouloir faire de la comm pour notre outil, tu peux facilement extraire la liste des crèches dont nous disposons des contacts sur Societeinfo (et il y’en a pas mal…)
@Papouille, je tuais le temps cet après midi et j’ai vu ce thread.
J’arrive un peu après la bataille mais si tu maîtrises a minima Python je te partage mon code. En ce moment même il mouline et il en est à +5000 emails
#!/usr/bin/env python
# coding: utf-8
#On importe quelques librairies utiles
import json
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
#On définit la fonction qui récupèrera les détails de chaque page interrogée
def getDetails(url):
#On interroge l'adresse
response = requests.get(url)
#Si la réponse est une erreur (la page n'existe pas), on interrompt la fonction
if response.status_code == 404:
return None
#BeautifulSoup sert à "parser" / décomposer les infos d'une page html
soup = BeautifulSoup(response.content)
#On extrait l'id de l'établissement
creche_id = url.split('/')[-1]
#On extrait le nom de l'établissement
name = soup.find('div', {'class':'marB20'}).find('h1').text
## Tout un tas de champs que l'on teste
#Le nom du gestionnaire
try:
manager = soup.find('p',text=re.compile("Gestionnaire"))
manager = manager.text.replace("Gestionnaire :",'').strip()
except:
manager = None
#La date de la création de la structure (si elle existe...)
try:
opening_date = soup.find('p',text=re.compile("Date d'ouverture"))
opening_date = opening_date.replace("Date d'ouverture :",'').strip()
except:
opening_date = None
#Et tous les autres champs qui nous interessent
try:
type_creche = soup.find('td',text=re.compile("Type de la structure")).find_next('td').contents[0]
except:
type_creche=None
try:
capacity = soup.find('td',text=re.compile("Capacité d'accueil")).find_next('td').contents[0]
except:
capacity=None
try:
geo = soup.select('div[data-leaflet*=latitude]')
geo = json.loads(geo[0].get('data-leaflet'))
lat = geo['center']['latitude']
lng = geo['center']['longitude']
except:
lat = lng = None
try:
info_table = soup.find(text=re.compile("Adresse e-mail")).find_parent('table')
full_address = info_table.find(text=re.compile("Adresse postale")).find_next('td').contents
address = full_address[0]
city = full_address[-1]
except:
address = city = None
try:
phone = info_table.find(text=re.compile("Numéro de téléphone")).find_next('td').contents[0]
except:
phone=None
try:
email = info_table.find(text=re.compile("Adresse e-mail")).find_next('td').contents[0]
email = email.text
except:
email=None
#Une fois fini, la fonction retourne les données extraites
return dict(creche_id = creche_id, name=name,capacity=capacity, manager=manager,
opening_date=opening_date,
address = address,city=city,
lat=lat, lng= lng, phone= phone, email=email)
#On génère une liste d'adresses que l'on va visiter
liste_url = []
#Ici on fait une boucle jusqu'à 100000 mais c'est une borne au hasard
#On trouve des réponses à ce niveau là
#Plus le chiffre est important, plus le script va être long
borne_max = 100000
for i in range(1, borne_max):
liste_url.append("https://www.journaldesfemmes.fr/maman/creches/-/creche-{}".format(i))
#Cette variable va stocker les resultats
creches_details_results = []
#On fait une boucle dans la liste d'adresses générées
for idx, creche in enumerate(liste_url):
print(creche)
#La variable ci-dessous appelle la fonction "getDetails" qui donne les détails par établissement
res = getDetails(creche)
#S'il n'y a pas de résultat on passe à l'adresse suivante
if res == None:
continue
#Sinon on ajoute le résultat à notre liste
creches_details_results.append(res)
print(len(creches_details_results), "crèches trouvées")
print(len([x for x in creches_details_results if x['email'] != None]), 'emails trouvés')
print(int((idx/borne_max)*100), "% accomplis")
print()
df = pd.DataFrame(creches_details_results)
df = df[['creche_id','name','capacity','manager', 'address', 'city', 'email',
'opening_date', 'phone', 'lat', 'lng']]
print(len(df.email.unique()), "adresses email uniques")
df.head(2)
#Export vers Excel
df.to_excel("output.xlsx", index=False)
Fonctionne en Python v3 et probablement aussi en v2.
merci beaucoup ! maintenant je me lance dans l’apprentissage de python , j’ai lu que c’est le code incontournable aujourd’hui alors go ahead merci beaucoup ! maintenant je me lance dans l’apprentissage de python , j’ai lu que c’est le code incontournable aujourd’hui alors go ahead
je dois apprendre python v1 et V2 ou directement python v3 ?



 merci beaucoup ! maintenant je me lance dans l’apprentissage de python , j’ai lu que c’est le code incontournable aujourd’hui alors go ahead
merci beaucoup ! maintenant je me lance dans l’apprentissage de python , j’ai lu que c’est le code incontournable aujourd’hui alors go ahead