@sem: Pour répondre à ta question, " GhostJS is a powerful wrapper and module for CasperJS"
Grossomodo, cette lib te permets d’écrire moins de code, avec des méthodes « wrapper » qui englobe des fonctions que l’on a l’habitude de sans cesse réutiliser.
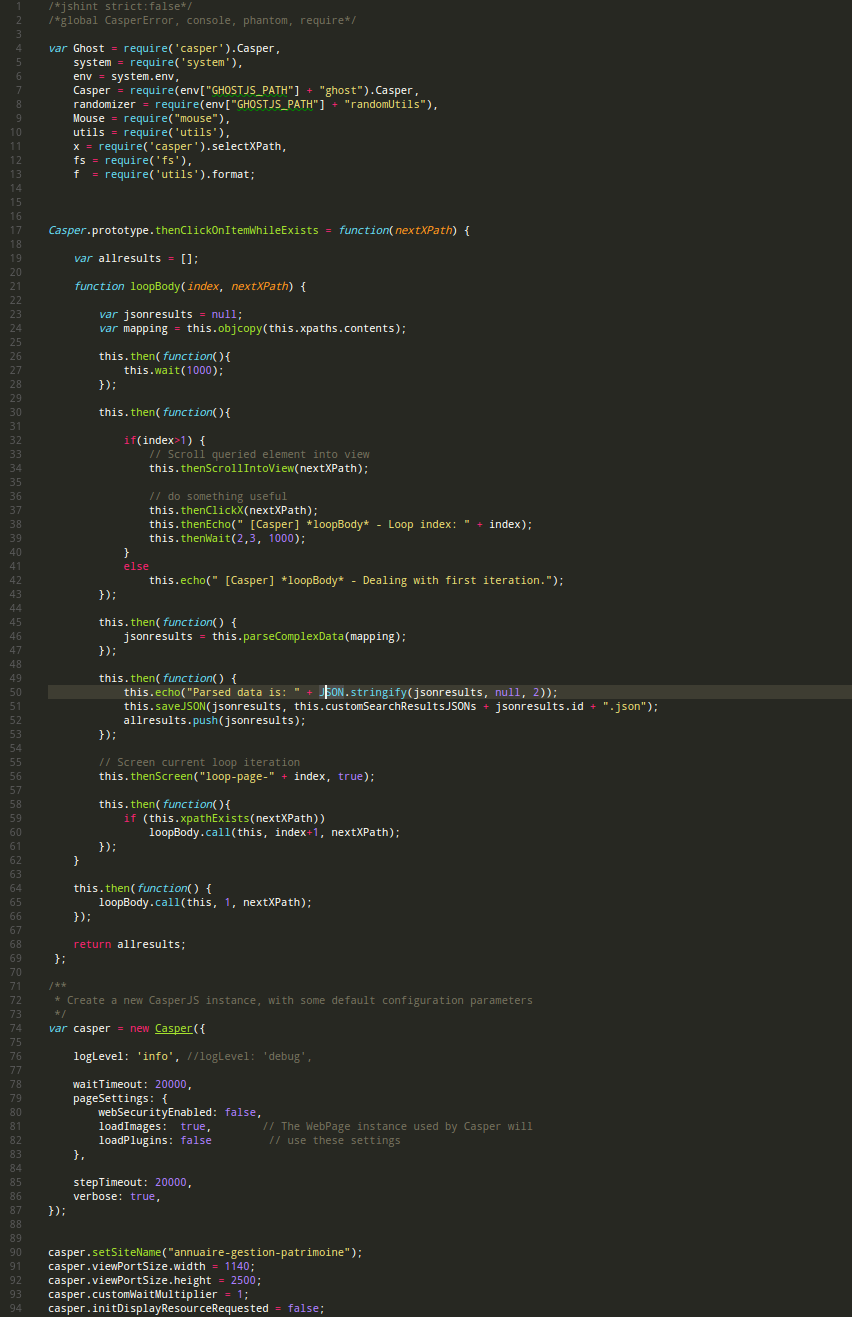
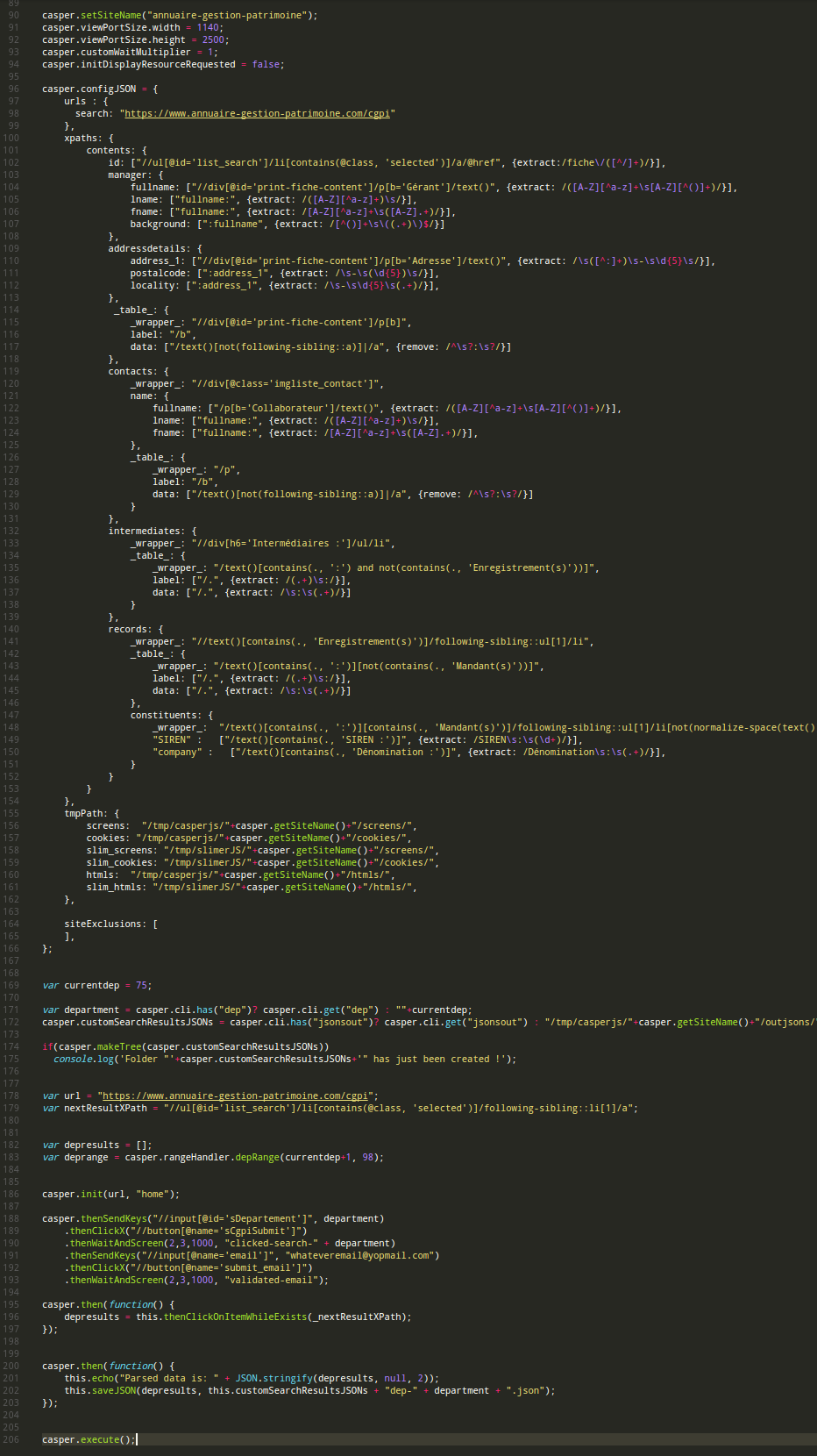
Par exemple, quand tu fais du CasperJS, les 3/4 du temps les appels aux fonctions sont placés dans des casper.then(function(){....}); , à cause de la nature asynchrone de PhantomJS, ce qui te permet de fonctionner en terme de « step » grâce à CasperJS, et d’y gagner en lisibilité et compréhension dans ce contexte asynchrone. Du coup, tu dois souvent écrire ici et là des casper.then autour des appels aux méthodes, ce qui alourdi considérablement le code.
Il est alors bien plus simple d’utiliser des méthodes du type (dont les noms sont suffisamment explicites):
- casper.thenWaitAndScreen
- casper.thenWaitAndSendKeys
- casper.clickOnLinkThenSavePageContentsThenBack
Exemple détaillé d’une méthode GhostJS:
/**
* Ghost operations: THEN WAIT + THEN CLICK + THEN SCREEN
* - Wait for a random time, defined by a min-max range, then click on a specific node element identified by its XPath, and take a screenshot
* - The random time range (min and max values) is expressed in millisecond, the 'multiplyWait' parameter should be used as the range multiplier, example: for a random 2-3 seconds range, minWait=2, maxWait=3 and multiplyWait=1000
* @param {number} minWait - The random time range min value (expressed in millisecond)
* @param {number} maxWait - The random time range max value (expressed in millisecond)
* @param {number} multiplyWait - The random time range multiplier value (should be 1000 if the time range is expressed in seconds)
* @param {string} xpath - The XPath identifying the node element to click on
* @param {string} screenName - The screenshot file name
* @param {bool} onlywhenitemexists - Only process this step if the node identified by the XPath does exist
*/
Ghost.prototype.thenWaitThenClickAndScreen =
/** @lends Ghost */
function(minWait, maxWait, multiplyWait, xpath, screenName, onlywhenitemexists) {
onlywhenitemexists = (onlywhenitemexists===null || onlywhenitemexists===undefined || !onlywhenitemexists)? false: true;
this.then(function() {
if((this.xpathExists(xpath) && onlywhenitemexists) || !onlywhenitemexists ) {
this.thenWaitThenClick(minWait, maxWait, multiplyWait, xpath);
this.thenWaitAndScreen(1, 2, 1000, screenName);
}
});
};
Voilà, c’est pour gagner du temps. La seule contrainte avant de pouvoir bien l’utiliser, c’est de maîtriser suffisamment les concepts de Phantom+CasperJS.
En effet les tutos de @boristchangang sont top