Salut la communauté,
j’ai besoin de votre aide.
Je souhaite scraper le site hxxps://lannuaire.service-public.fr/aquitaine-limousin-poitou-charentes#service-mairie pour récupérer les adresses mails qui figurent dans une fiche (page) sous cette forme : adriers [ à ] cg86.fr
Comment faire et comment gérer la pagination?
Merci d’avance
Incroyable ! L’administration a une API ![]() !
!
En cherchant à répondre ta question, je suis tombé sur ça:
https://lannuaire.service-public.fr/aquitaine-limousin-poitou-charentes/services/mairie
Cette api retourne l’ensemble des coordonnées des mairies, par département pour aquitaine-limousin-poitou-charentes. Tu peux remplacer cette string par une autre region apparemment (``ìle-de-france- fonctionne par exemple).
Il y a surement une API pour le details d’une mairie, mais je ne l’ai pas trouvé…si qq1 est motivé pour la chercher ![]()
Par contre, dans google spreadsheet, tu peux extraire très rapidement l’ensemble des emails des urls retournées par l’API ci-dessus:
1. En colonne A
Extrais la liste des urls depuis l’API (http://www.jsonquerytool.com/)
Puis colle la en colonne A (en y ajoutant le root domaine évidemment).
2. En colonne B
On va extraire les emails pour chaque url de la colonne A, et les convertir en vrai emails:
Utilise la formule suivante:
=regexreplace(importxml(A4;"//li/span[@class='contact-detail']");"( \[ à \] )";"@")
Done.
6 « J'aime »
Excellent, merci cebri pour ton retour.
dernier détail peux-tu m’expliquer comment utiliser http://www.jsonquerytool.com/
Merci d’avance
1fan2 deux.io
En fait il faut que tu copies les datas au format Json dans la case Json.
Après l’extraction query tu mets $url
(Fais bien attention de te mettre en Xpath for JSON quand même…)
Puis après tu n’as plus qu’à copier les urls.
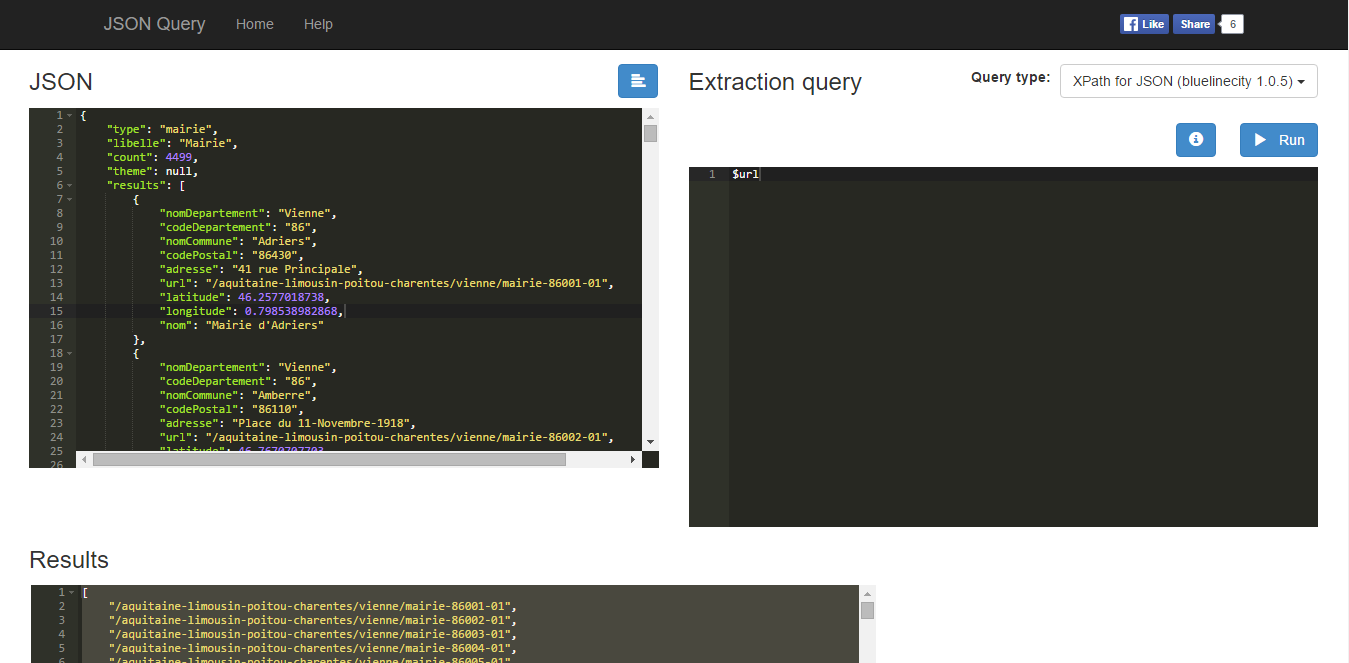
Un peu de nettoyage, une concatenate avec le root domain et hop !
Tu n’as plus qu’à copier le regex de @cebri et c’est bon ![]()
Si jamais tu es pressé tu l’as ici
Bon week end
2 « J'aime »
Merci VivianSolide bon week end à toi
Si tu donnes un poisson à un homme, il mangera un jour. Si tu lui apprends à pêcher, il mangera toujours
5 « J'aime »
Salut,
Je suis pas déveloper et j’avoue que j’ai pas compris les démarches à suivre pour Json…
Ensuite le google spreadsheet ne fonctionne pas chez moi, il n’extrait pas les adresses mail.
Hello Charles, tu as trouvé une solution depuis?
j’ai le script pour le faire si tu veux. Pas optimisé, mais il tourne
Salut,
J’apprends à coder sur ruby, j’ai utilisé Nokogiri. Si je peux me permettre, un conseil à tous, apprenez à coder, vous verrez vous arriverez à faire du growth hacking.
2 « J'aime »
Bonjour,
Je voudrais faire quelque chose d’assez similaire : à partir de https://lannuaire.service-public.fr/corse/services/mairie je voudrais reconstituer un fichier excel propre avec toutes les infos correctement ordonnées.
Je n’ai pas beaucoup de connaissance en codage. Si quelqu’un connait une méthode simple ? Je pensais à utiliser rechercher/remplacer sous excel pour reconstituer des séparateurs qu’excel reconnaisse. A moin que quelqu’un ait un script tout prêt qui fasse le travail.
Merci d’avance.
Re-bonjour,
J’ai réussi à reconstituer un tableau excel avec tout au propre. J’essaye maintenant de scraper les mails mais je suis limité par google sheet à 50 impor xml. Est-ce que quelqu’un aurait une solution ?
Quelqu’un saurait fournir l’export sitemape sous web scraper chrome (http://webscraper.io) pour récupération des infos des mairies sur https://lannuaire.service-public.fr/ ?
Mon SiteMape boucle sur le selector « page suivante » sans scraper les infos
En revanche je peux scrapper les infos mairies sur la premiere page uniquement , si je n’utilise pas le selector « page suivante »
{« _id »:« service-public »,« startUrl »:« 36038 Résultat(s) pour votre recherche : Mairie - page 1 sur 1202 - Annuaire | Service-Public.fr a »,« delay »:« »},{« parentSelectors »:[« liste-mairie »],« type »:« SelectorText »,« multiple »:false,« id »:« nom »,« selector »:« h1 »,« regex »:« »,« delay »:« »},{« parentSelectors »:[« liste-mairie »],« type »:« SelectorText »,« multiple »:false,« id »:« adresse »,« selector »:« div.annuaire-bloc:nth-of-type(1) p »,« regex »:« »,« delay »:« »},{« parentSelectors »:[« liste-mairie »],« type »:« SelectorText »,« multiple »:false,« id »:« mail »,« selector »:« a.contact-detail »,« regex »:« »,« delay »:« »},{« parentSelectors »:[« liste-mairie »],« type »:« SelectorText »,« multiple »:false,« id »:« telephone »,« selector »:« span#contentPhone_1 »,« regex »:« »,« delay »:« »},{« parentSelectors »:[« _root »,« next »],« type »:« SelectorLink »,« multiple »:false,« id »:« next »,« selector »:« li.next a »,« delay »:« »}]}
Hello,
Problème toujours non résolu?
@cebri, puis-je te demander comment tu as fait pour trouver l’URL de l’API ? j’ai bien essayé de chercher avec le XHR, mais je bloque… merci ![]()
C’est un peu loin @Gombi ![]() je ne me souviens pas du tout…j’ai du fouiller…
je ne me souviens pas du tout…j’ai du fouiller…
Sinon toutes les données proviennent de, et sont disponibles au format XML ici même:
3 « J'aime »
Merci quand même ![]()
Hello, je suis aussi a la recherche d’une methode pour scraper les emails de toutes les mairies… tu as pu trouver une solution depuis ?
Merci
Delphine
Je suis car cela m’intéresse également