Bonjour a tous,
Je cherche un moyen de scraper uniquement les résultats sponsorisées de tripadvisor.
J’ai essayer de trouver un foorptint mais pas vraiment évident.
Des idées ?
Merci
Bonjour a tous,
Je cherche un moyen de scraper uniquement les résultats sponsorisées de tripadvisor.
J’ai essayer de trouver un foorptint mais pas vraiment évident.
Des idées ?
Merci
Comment tu fais pour savoir que c’est un résultat sponsorisé ?
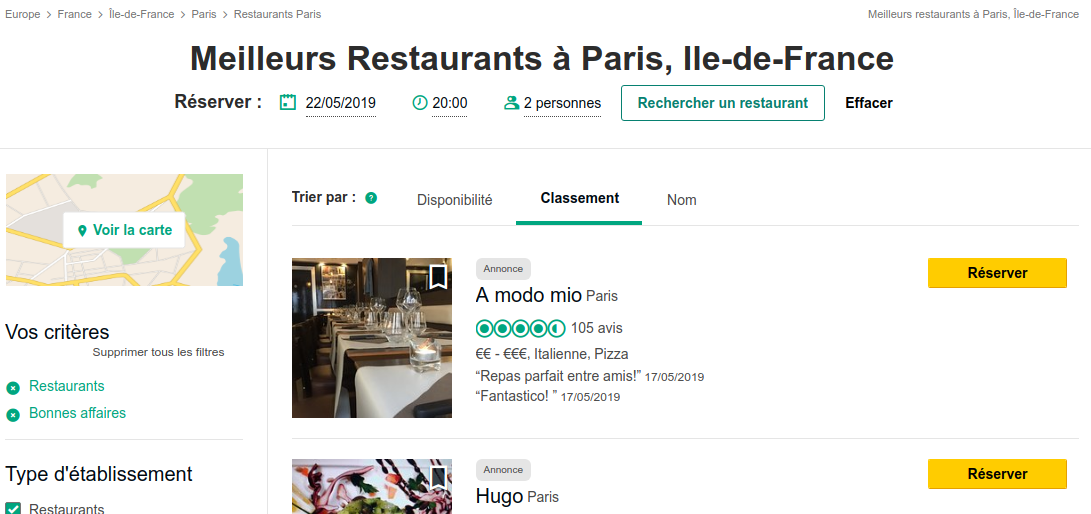
Je me demande si il ne s’agit pas de ceux repérables via le petit flag « Annonce » en gris au dessus du nom de l’établissement?
@ScrapingExpert oui effectivement c’est ce que j’avais identifier mais impossible de trouver un footprint sur cet element
Le principe d’une empreinte, c’est d’arriver à distinguer ce qui est commun à un ensemble de pages tout en écartant les autres.
exemple: intext: »Logiciel e-commerce par PrestaShop » +inurl:best-sales pour identifier les meilleures ventes sur les boutiques prestashop
D’accord, oui je vois ce qu’est un footprint mais tu n’avais pas dis à partir de quelle source 
Tu veux donc ici pouvoir identifier les résultats sponsorisés au sein de TripAdvisor, mais depuis Google.
Si je comprends bien le problème que tu rencontres:
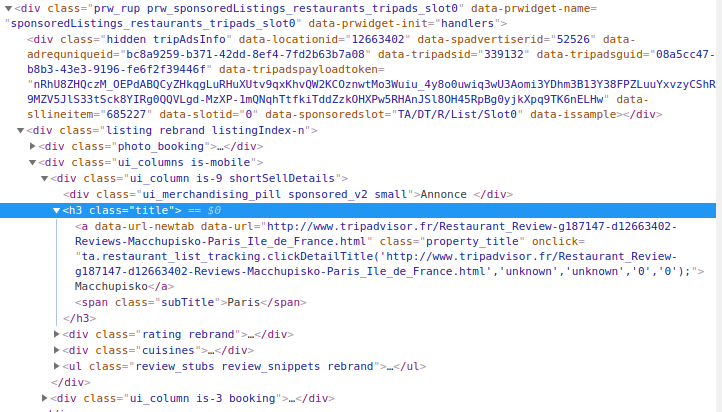
Pour y arriver, il faut que les URL des pages ciblées (c’est à dire les liens des pages des établissements qui sont sponsorisés) contiennent un élément différenciant. Or sur Tripadvisor, tous les liens sont les mêmes avec la même structure dans les pages de résultats, que l’établissement soit sponsorisé, ou non:
Ce qui rend cette méthode non fonctionnelle ici 
Une autre possibilité, ça serait de :
Récupérer les liens des pages de résultats pour chaque ville de France, par exemple: https://www.tripadvisor.fr/Restaurants-g187147-Paris_Ile_de_France.html
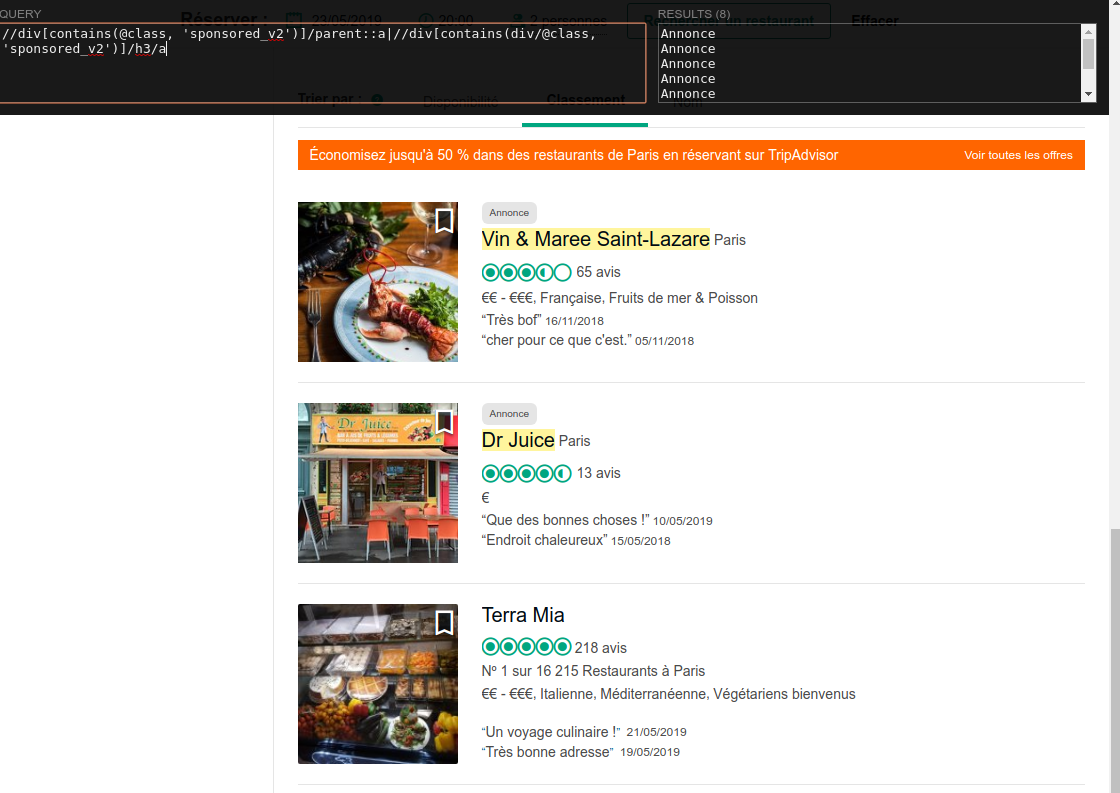
A partir de là, browser chacune de ces pages, et scraper les annonces sponsorisées après avoir écrit le sélecteur CSS/XPath qui identifie ces annonces:
//div[contains(@class, 'sponsored_v2')]/parent::a|//div[contains(div/@class, 'sponsored_v2')]/h3/a
a>div.sponsored_v2, div.sponsored_v2+h3>a
(La 1ère partie sur sélecteur CSS ne permet pas de cibler directement les liens, puisqu’on ne peut identifier de manière unique que le div enfant, sans pouvoir remonter au parent a, contrairement à XPath)
Oui c’est exactement ça je voulais le faire depuis google mais effectivement c’est beaucoup trop limité pour ce que je veux faire.
Oui j’avais pensé au scraping mais je voulais éviter de mettre les mains dans le code.
Tu connaîtrais pas un outils qui permettrait de s’en sortir sans coder ?
![]()
![]()
![]()
@Mohamed_Asb1 malheureusement ce n’est pas mon point fort, je fais quasi tout en code, et ne connais pas assez les outils « sans code ». Honte à moi 
Il y a bien Google Spreadsheet avec la fonctionnalité importXML je crois, mais c’est assez bugué je trouve, pas sûr qu’il prenne en compte un XPath comme écrit au dessus. Et puis il te faudrait être en mesure d’extraire les URLs de toutes les pages villes avant. Peut être que tu peux regarder de ce coté là?
OK je vais essayer de chercher un peu.
En tous cas je te remercie de ton aide.
Je sais pas si tu avais trouvé cette page mais ici, tu as toutes les villes de France :