Je continue de m’amuser à apprendre des choses simples du scrapping, avec des outils gratuits.
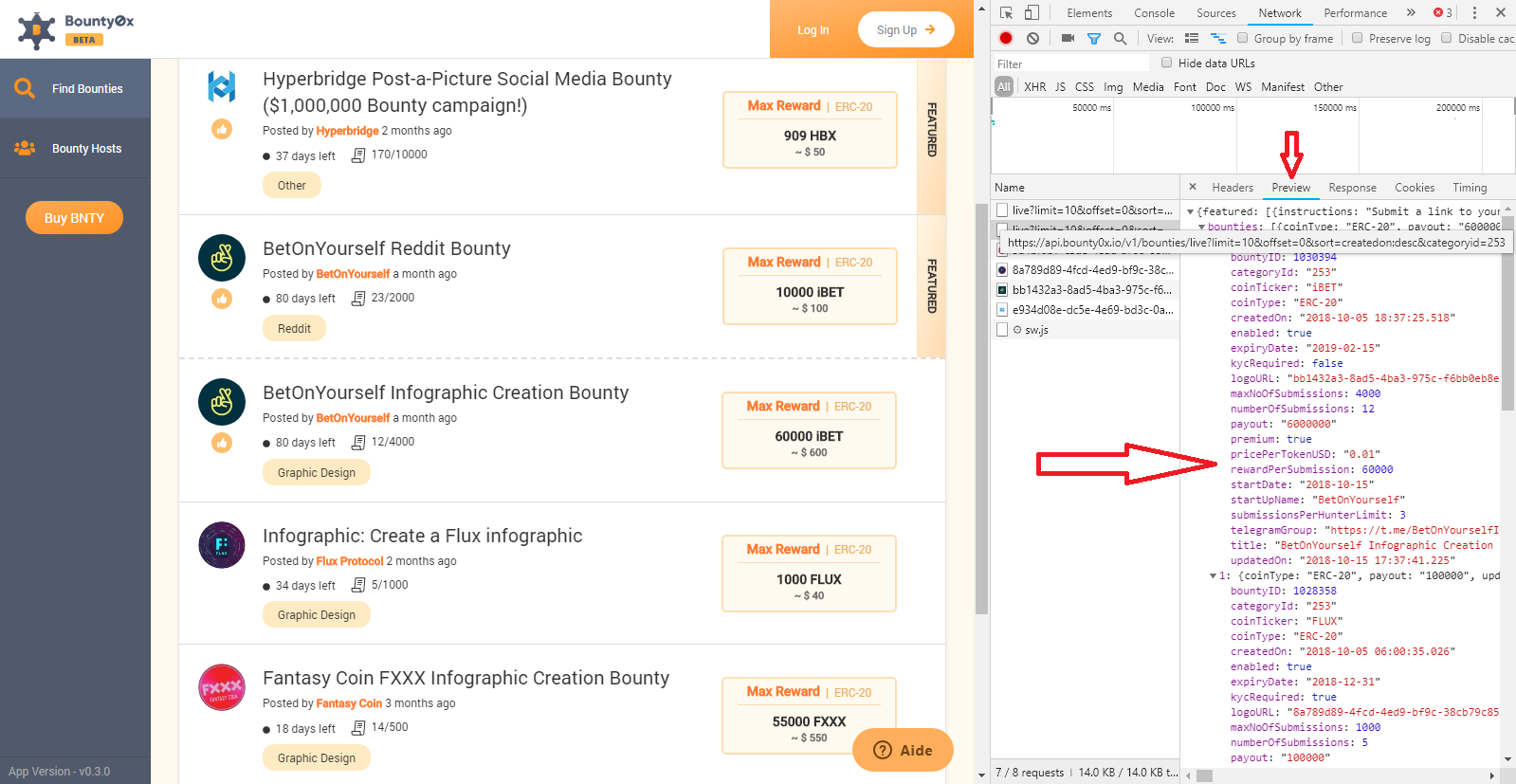
Je souhaiterais scrapper tous les projets de ce site proposant un bounty d’une certaine catégorie (par exemple les articles).
Sur le site, il faut cliquer sur filtrer les projets, choisir la catégorie « article » pour faire apparaitre les projets. https://beta.bounty0x.io/bounties/
Évidemment, quand je me rends sur l’url j’ai un message d’erreur « application non autorisée ».
Y’a-t-il un moyen facile d’accéder à ces contenus malgré tout ?
Merci, cela va raccourcir déjà la démarche.
Je vais regarder ça en détail.
Idéalement, j’aurais aimé l’automatiser (que ce soit mis à jour en direct), ce qui n’est pas possible avec cette méthode.
Il faut d’ailleurs répéter l’opération pour chaque page avec ton système, c’est ça ?
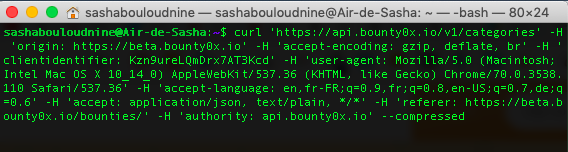
Effectivement, il ne suffit pas de l’URL pour faire une requête mais d’un ensemble d’élément, le Headers, les Cookies, etc… qui vont habiller ta « requête », comme s’il s’agissait de celle d’un vrai utilisateur.
Si tu veux rapidement tester une requête, il faut aller sur la partie « Network » de ton navigateur, copier/coller la requête qui t’intéresse en cURL, et la coller dans ton terminal.
Si tu veux éviter d’avoir à te taper tous les headers pour envoyer une requête, l’automatisation de ce type d’action dans un contexte « web browser » sera beaucoup plus aisée via l’implémentation avec une techno de type headless browser comme avec Nodejs + Puppeteer : )