Hello @Alvesinho,
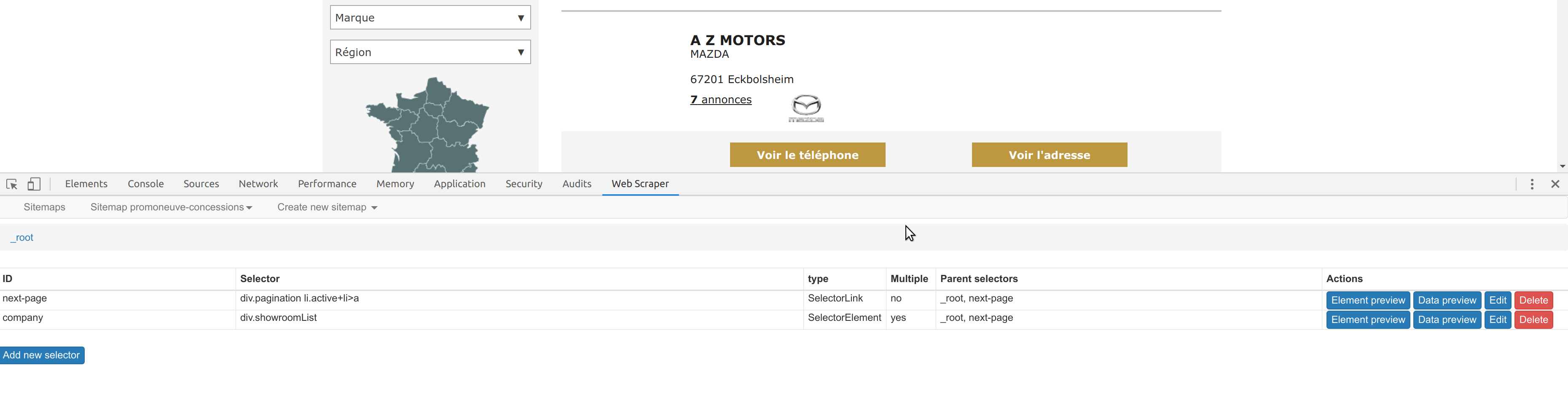
Les sélecteurs CSS que tu as choisi pour l’extraction des données sont justes.
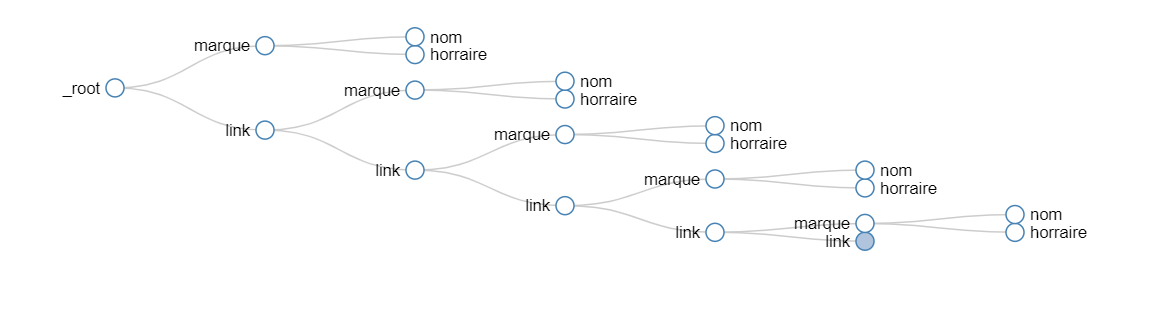
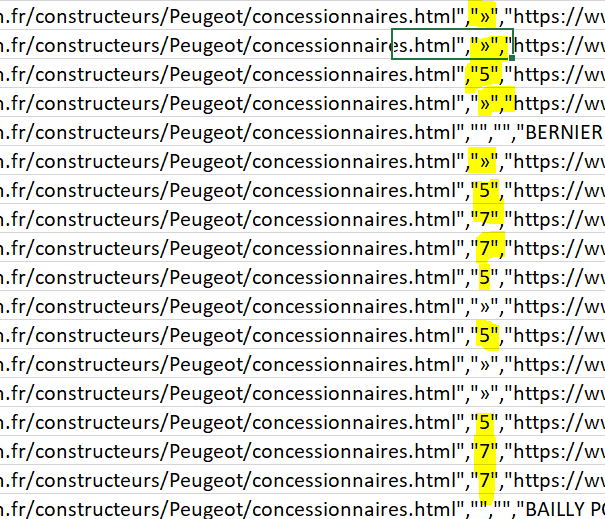
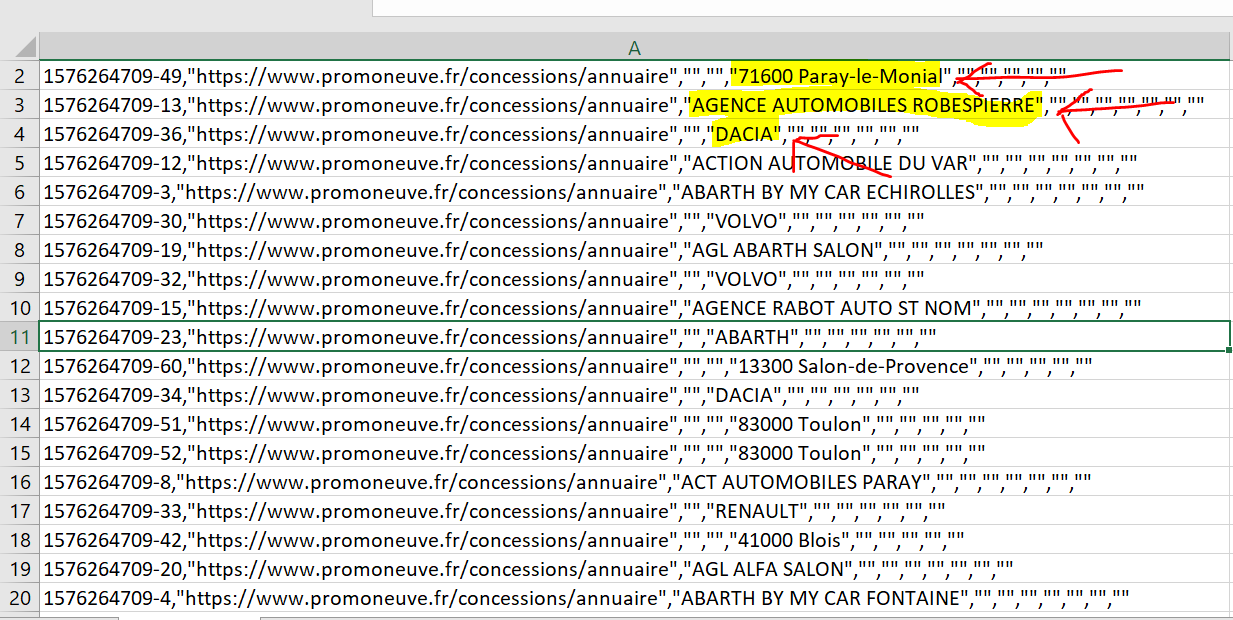
En revanche, ce qui pose problème c’est le sélecteur « parent », celui qui défini l’élément qui englobe chacun des trois champs que tu souhaites extraire. Si celui-ci est incorrect, on se retrouve avec des trous dans les champs extraits.
Voici les sélecteurs que j’ai utilisé, et ensuite l’export de ma config (le sitemap JSON):
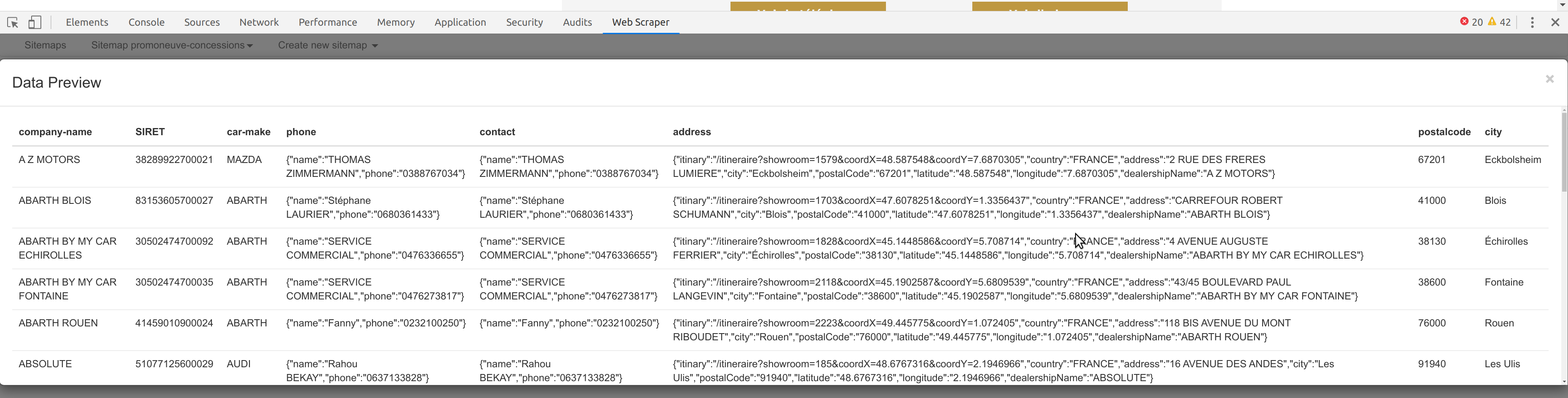
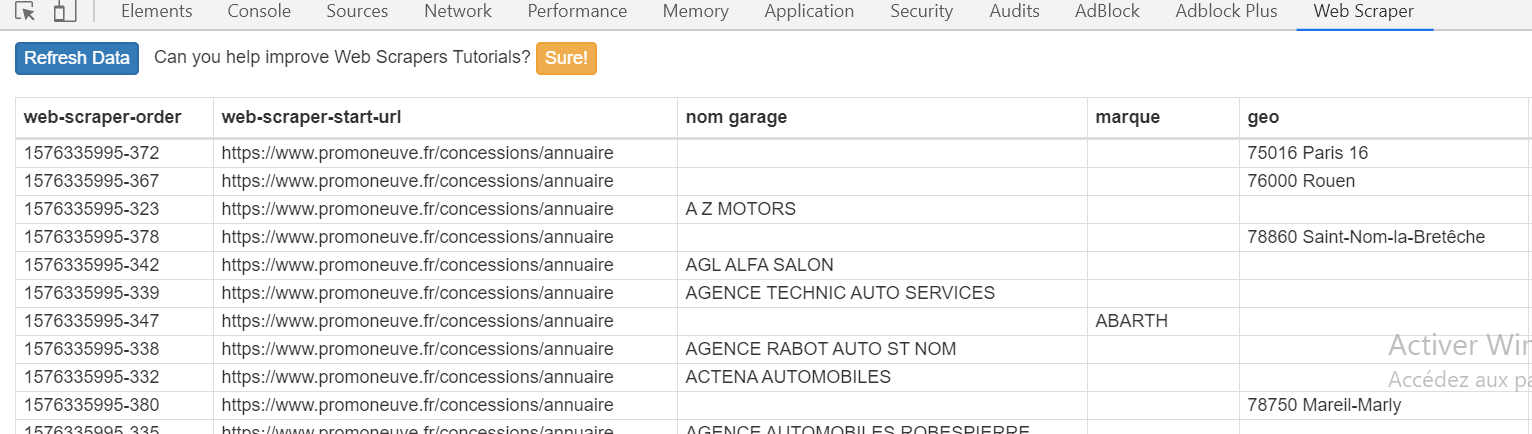
Résultat des données extraites, sans « trous »:
La config JSON que j’ai exporté, si tu veux la réimporter dans ton WebScraper:
{"_id":"promoneuve-concessions","startUrl":["https://www.promoneuve.fr/concessions/annuaire"],"selectors":[{"id":"next-page","type":"SelectorLink","parentSelectors":["_root","next-page"],"selector":"div.pagination li.active+li>a","multiple":false,"delay":0},{"id":"company","type":"SelectorElement","parentSelectors":["_root","next-page"],"selector":"div.showroomList","multiple":true,"delay":0},{"id":"company-name","type":"SelectorText","parentSelectors":["company"],"selector":"a>strong.text-upper","multiple":false,"regex":"","delay":0},{"id":"SIRET","type":"SelectorText","parentSelectors":["company"],"selector":"a>span.hidden","multiple":false,"regex":"","delay":0},{"id":"car-make","type":"SelectorText","parentSelectors":["company"],"selector":"a>span.text-regular","multiple":false,"regex":"","delay":0},{"id":"phone","type":"SelectorElementAttribute","parentSelectors":["company"],"selector":"a[data-target='#phone-numberModal']","multiple":false,"extractAttribute":"data-contact-1","delay":0},{"id":"contact","type":"SelectorElementAttribute","parentSelectors":["company"],"selector":"a[data-target='#phone-numberModal']","multiple":false,"extractAttribute":"data-contact-1","delay":0},{"id":"address","type":"SelectorElementAttribute","parentSelectors":["company"],"selector":"a[data-map]","multiple":false,"extractAttribute":"data-map","delay":0},{"id":"postalcode","type":"SelectorText","parentSelectors":["company"],"selector":"span.text-black","multiple":false,"regex":"[0-9]{5}","delay":0},{"id":"city","type":"SelectorText","parentSelectors":["company"],"selector":"span.text-black","multiple":false,"regex":"[^\\s\\d].+","delay":0}]}
 Peux tu essayer de réécrire tes sélecteurs CSS pour mieux cibler les éléments à extraire?
Peux tu essayer de réécrire tes sélecteurs CSS pour mieux cibler les éléments à extraire?