Bonjour,
Depuis quelques jours j’essaye de scraper un site internet sur ses résultats de recherche.
« http://www.mygaloo.fr/annuaire-associations/statut_Registered_NotRegistered_Unknown/ »
Je recherche à avoir la totalité de liens vers les association exemple :
« http://www.mygaloo.fr/association-description/consud »
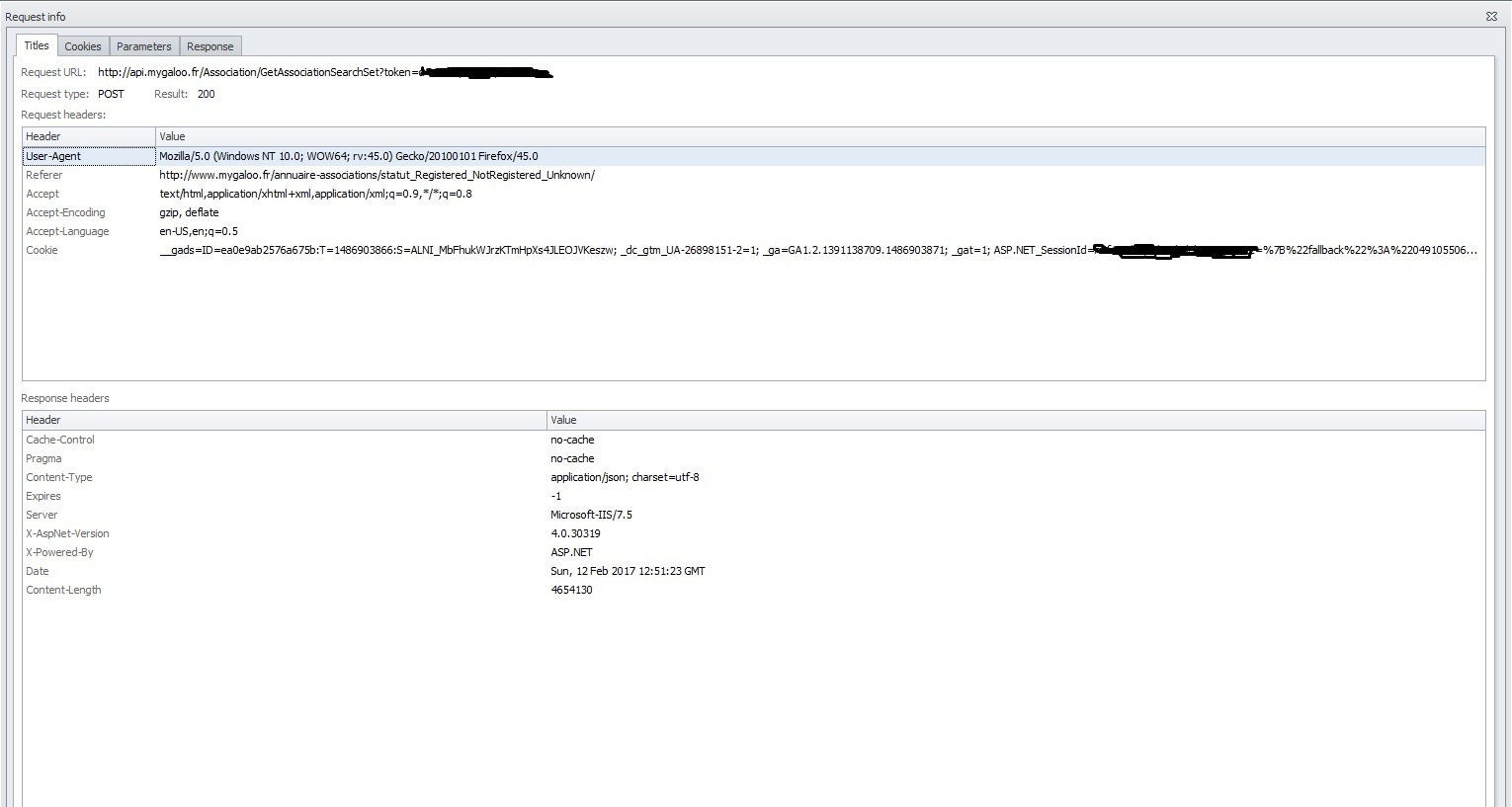
Quand on lance une recherche, le site envoi à API une requête POST avec Access-Control-Allow-Origin pour récupérer ses résultats, 20 résultats de recherches sont alors affiché et un bouton « plus de résultats » s’affiche qui lui aussi envoi une requête POST avec ACAO.
J’ai essayé de lancer un instance de chrome qui simule le scroll et l’appui sur le bouton « Plus de résultats » mais au bout de 300-400 requête plus rien ne s’affiche alors que d’après api il y aurait plus de 50 000 pages disponibles, et je ne comprend pas pourquoi (l’instance ne dépasse pas 1Go de RAM, chrome ne plante pas et au vu du fait que nombres de requêtes pour que cela bug est aléatoire je ne pense pas que cela soit un règles coté Server)
Mon petit programme est en Ruby.
Pourriez-vous m’aider ?
Merci à vous.