L’api mobile n’est pas protégée par datadome ?
1 « J'aime »
non, elle l’est pas ![]()
2 « J'aime »
elle l’est
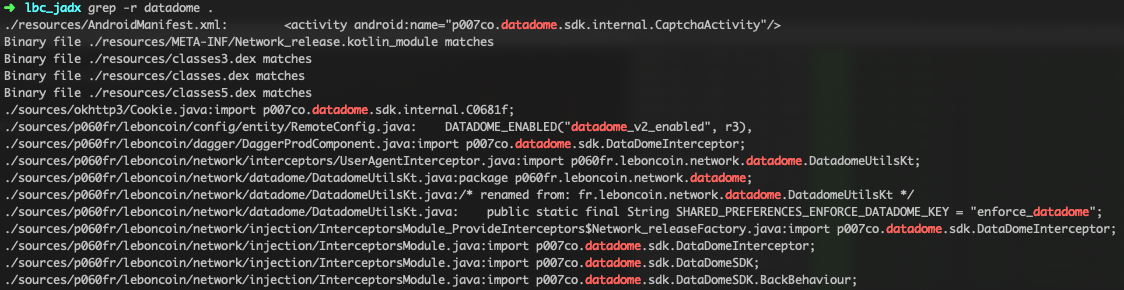
ils ont installé leur SDK qui fait des trucs en tout cas
si t’as réussi a bypass leur check de touchevents etc et que t’as une piste on est preneur ^^
2 « J'aime »
Ok super intéressant tout ça, on ne dirait pas non à un petit tuto ![]() , surtout si ça fonctionne bien !
, surtout si ça fonctionne bien !
1 « J'aime »
Nous n’avons pas encore essayer, mais pour l’avoir fait pour instagram, cela avait plutôt bien marché. Si l’on arrive à quelque chose je vous tiens au jus !
1 « J'aime »
Hello. Ce post est super intéressant car j’ai moi même lancé un produit il y a 2 mois basé sur le scraping du site Leboncoin pour envoyer des notifications des nouvelles annonces immo en temps réel sur Telegram ( c’est largement plus pratique que les emails). Contourner datadom est pas simple mais je le trouve super fun.
Mon produit c’est https://nimobi.fr que vous pouvez utiliser gratuitement en phase bêta.
Je tourne à 100 req/heure et ça suffit bien pour mon use case. La plus grande difficulté c’est d’être sûr de ne rater aucune annonce, et ça c’est pas simple vu comme lbc est foutu.
3 « J'aime »
Bonjour à tous !
j’ai besoin pour un projet de récupérer certaines informations d’une annonce leboncoin, à la demande l’utilisateur ( il copie le lien dans un input et je lui retourne un tableau d’information contenant le prix, le lieu etc )
j’arrive a l’aide de puppeteer-firefox d’acceder à ces informations mais seulement une fois, la seconde fois mon ip est bloquée par datadome. Je pense me tourner vers une rotation d’ip mais j’aimerais pouvoir tester avant de prendre une solution payante connaissez vous des solutions gratuites qui fonctionnent ?
Merci
La première version (la v1) de Datadome de 2016-2017 utilisait banalement cette librairie JS : GitHub - fingerprintjs/fingerprintjs: The most advanced browser fingerprinting library.
Ils ont basculé vers une première version de leur propre code en octobre 2017 (la v2) et la version que l’on a aujourd’hui (la v3) date a été introduite en juin 2018. Bien sûr, elle évolue constamment… en dehors de ces 3 versions majeures, j’ai dénombré une petite centaine de vesions mineures depuis leurs débuts.
Le concept est le même depuis le début : collecter un maximum d’informations sur votre environnement (navigateur, système) ainsi que sur vos interractions avec le site pour générer une « empreinte digitale » de votre poste et vérifier que la façon d’on vous surfez n’est pas celle d’un robot.
Après, en dehors du besoin pour leurs clients d’éviter le pillage de leurs données, le volume de données envoyées à Datadome est effrayant : nombre et détails des mouvements de souris, nombre de clics, de scrolls, de touches pressées, votre ip privée, le nom de votre carte graphique, …
2 « J'aime »
@binaryreporter
Effectivement le nombre d’infos recolté par Datadom est effrayant…quelle serait donc la solution (ou l’idée ) pour palier à cela ?
Bien joué !
De mon côté Pygoo.fr et Pyget.fr tourne toujours ![]() et commence à avoir une bonne base d’utilisateurs, ça commence à faire beaucoup de requêtes par jour
et commence à avoir une bonne base d’utilisateurs, ça commence à faire beaucoup de requêtes par jour ![]()
C’est pas simple de faire du scraping en temps réel avec Leboncoin mais c’est faisable ![]()
Bravo pour ta solution @practagarus
@Neeko Merci tu as pu tester https://nimobi.fr ? J’aimerai bien avoir ton avis dessus ![]()
Tu as réussi à faire partir quelque uns de mes users qui m’ont fait un feedback ils ont l’air contents. Bravo à toi! Mais attention je vais les faire revenir, c’est qu’une question de temps ![]()
@nico30000 Rotation d’ips et espacer un peu les requêtes. Sinon c’est pas normal que tu sois bloqué au bout de seulement 2 requêtes.
1 « J'aime »
Hello , As tu une version équivalente a nimobi pour les autres catégories ( ex: véhicules ) … je serai intéressé .
Merci
1 « J'aime »
Pour les petits besoins il vaut mieux utiliser un système de scraping dans ton navigateur (type extension). Pour le scraping de masse, puppeteer bien configuré & de bons proxy reste imbattable, bine que plus chers (mais faut savoir ce qu’on veut).
Je récupère 80% de LBC pour mes clients comme ça, datadome me pose aucun soucis.
De toute façon, puppeteer (ou de façon général le headless) et de bons proxy (qui coûtent chers) est la solution ultime du crawling, et est pour le moment impossible à bloquer.
Très peu de site (européen) mettent en place des techniques ultra poussée (et encore plus chers à contrecarré) comme c’est le cas pour les sneakers par exemple (qui est un marché de prospection avant même qu’une paire sorte).
2 « J'aime »
@clementoo C’est dans la roadmap mais pour l’instant je focalise sur l’immobilier. Quand tout sera rodé je passerai aux autres catégories.
J’ai aussi un bot LBC qui marche bien, j’ai longuement hésité en faire un SaaS comme vous @practagarus @Neeko @magicjo.
Mais les risques juridique m’ont clairement ralenti.
Vous craignez pas que LBC vous attaque en justice dans le cas où vos projets se mettent à générer vraiment beaucoup de traffic ?
Selon moi le seul moyen d’être tranquille avec un SaaS de ce genre est d’avoir une structure juridique et financière offshore mais faut vraiment être déterminé.
De mon côté si je me met à vendre la solution je pensais plutôt à faire un truc fermé en allant chercher les clients IRL, j’imagine que c’est ce que tu fais @raz101 ?
2 « J'aime »
Il y a plusieurs jurisprudence sur ce sujet, notamment d’un point de vue européen. Si tu transforme suffisament les données, et que tu ne scrapes rien de privé (demandant de créer un compte, ou dont l’user à spécifiquement dit qu’il ne souhaités pas la réutilisation, etc…), ou que tu changes le contexte des données (méta moteur inter website par ex) tu ne crainds rien, en tout cas à l’instant T, faut voir comment la situation évolue.
Et puis, pense bien qu’à ton échelle, le scraping de données des centaines de comparateurs (vols, hotels, etc…) est bien plus important que le tiens.
De mon côté j’ai un site commercial, mais pas identifié LBC, plutôt généraliste. Pleins d’acteur existent déjà pour LBC, et à part le fait que tu sois moins chers, ai un bon réseau ou ai une offre à réelle valeur ajoutée, c’est un marché un peu bouché, ce que n’ai pas (encore tout du moins) le scraping généraliste.
2 « J'aime »
@raz101 a plutôt bien résumé la situation actuelle d’un point de vue légal.
Immoji est pensé comme un aggrégateur, et en ça on ne fait qu’indexer des pages comme un moteur de recherche le ferait. Lorsqu’une personne clique sur un de nos liens il est redirigé vers la plateforme d’origine. Bien sûr cela n’empêcherait pas SeLoger ou LBC de nous mettre des bâtons dans les roues. Pour le moment on est en mode « tant qu’ils ne grondent pas on fonce » . Plusieurs boîtes (loueragile, teddi.co etc…) ont adopté la stratégie du « clos » / « fermé », ils promettent d’envoyer des annonces dès qu’elles apparaissent sur des « centaines de sites ». Ce n’est pas dit implicitement, mais tout le monde sait qu’ils scrappent les grandes plateformes immobilières et pour le moment sans être inquiétés. Donc tu peux très clairement t’en inspirer ![]()
2 « J'aime »
Bonjour !
J’aurais aimé savoir qu’est ce que vous appelez de bons proxy ? Notamment @raz101 si t’en as à conseiller et que pensez vous des services de proxies comme crawlera ?
Super intéressant comme sujet ca donne déjà quelques pistes à suivre ![]()
![]()
Merci et bonne journée à tous
@owendittmer Perso je suis pas encore décidé sur ce point. Je peux très bien opérer en mode privé, mais je me dit aussi que en principe indéxer des annonces immo (rien de privé comme dit @raz101) on devrait être safe. Je ne suis malheureusement pas expert en la matière pour juger.
Au pire, je fait de la vente de proxy optimisé pour lbc ![]()
1 « J'aime »
Un bon proxy est un proxy qui correspond à ton besoin. Bon réponse inutile mais réelle.
De notre côté un bon proxy est un service qui a un taux de succès > à 85% selon nos besoins.
Crawlera est pas mal tant qu’il n’y a pas de grosse protection sur les sites sources.
On a un très gros abonnement chez luminati.io qui est le meilleur service à mon sens, mais aussi le plus chers (si vous créez un compte demandez moi mon lien affilié tant qu’à faire hihi).
Au final, on réduit de plus en plus nos services de proxy, on passe tout sur luminati qui, bien configuré, donne des taux de succès > 95%, et pour nos requêtes en big data c’est pas négligeable ce +10%.
Pour d’autres services on utilise aussi stormproxy par exemple. Et un autre vieux services utilises des proxy gratuits via une solution maison pour récupérer des proxy à travers les multiples sites de listing.
Donc, pour en revenir à ma phrase initiale, si ça ne te dérange pas de faire 3/4 retry sur une URL pour avoir l’info, un service proxy avec un faible % de succès (et généralement moins chers) te suffira largement.
4 « J'aime »