Bonjour à tous,
Je scrape depuis pas mal de temps avec l’extension Chrome « Web Scraper » et comme toujours, dès qu’il y a un site qui fonctionne avec du javascript ou avec une interface un peu complexe, impossible de scraper…
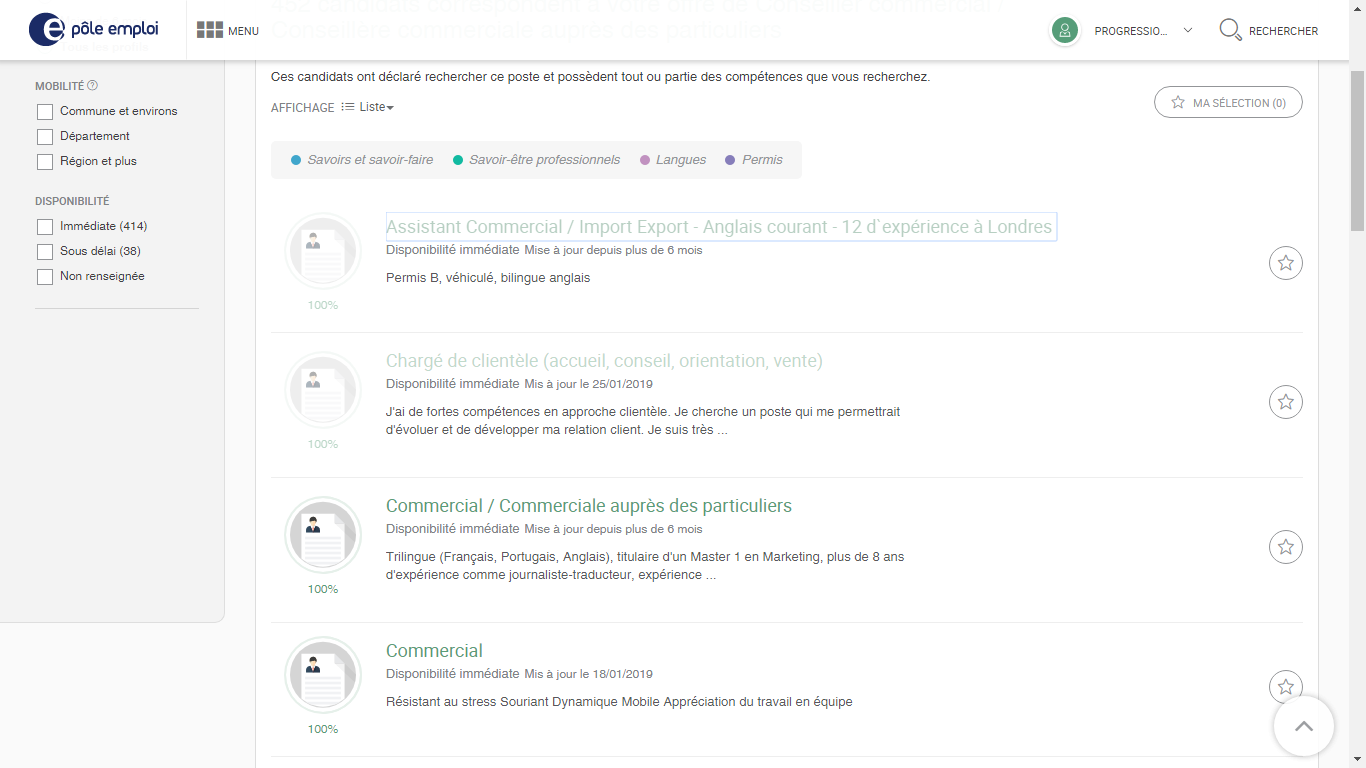
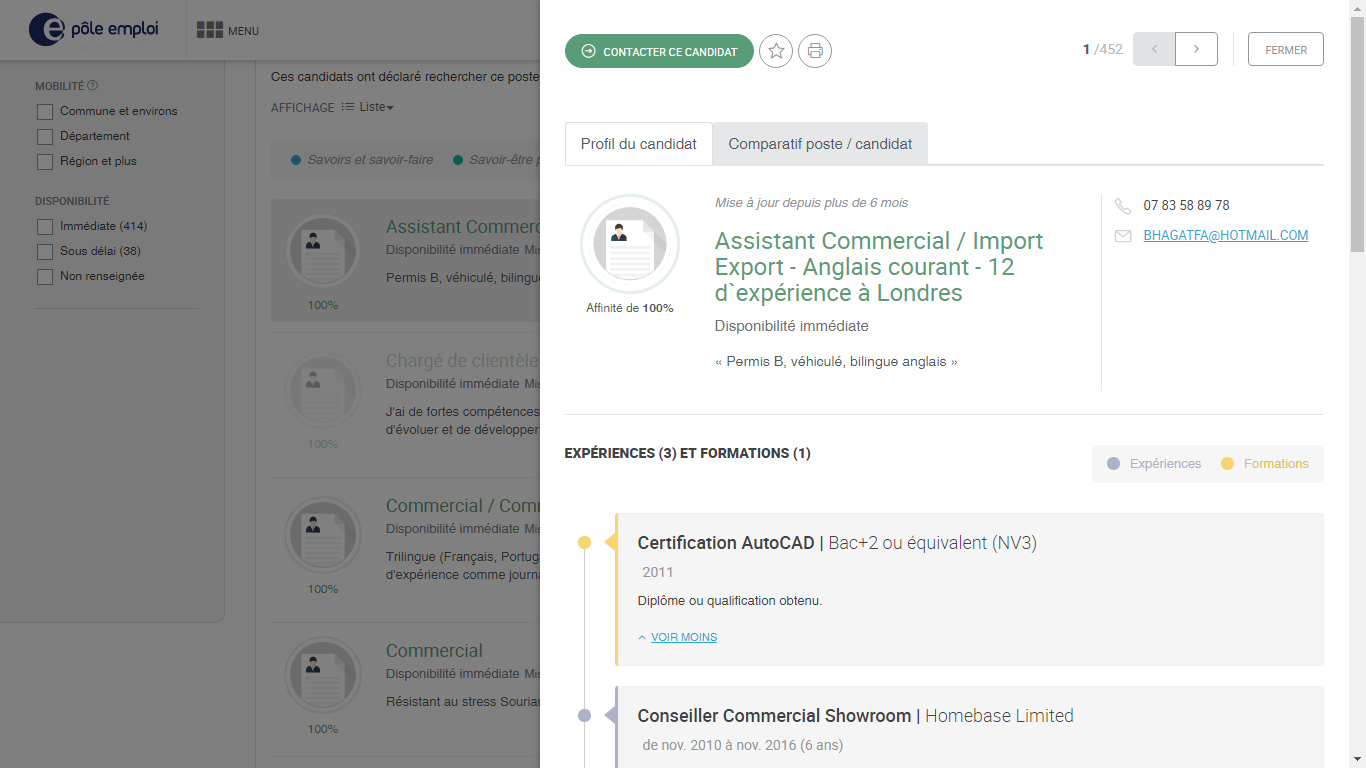
Voici des screens de la page en question et voici mon code, juste après :
{"_id":"pole-emploi","startUrl":["https://entreprise.pole-emploi.fr/recherche-profil/rechercheprofil?idOffre=082WGKY"],"selectors":[{"id":"element","type":"SelectorElement","parentSelectors":["next","debut"],"selector":"div.profil-hd-content div.media","multiple":false,"delay":0},{"id":"num","type":"SelectorText","parentSelectors":["element"],"selector":"dd:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"titre","type":"SelectorText","parentSelectors":["element"],"selector":"span.text-entreprise","multiple":false,"regex":"","delay":0},{"id":"email","type":"SelectorText","parentSelectors":["element"],"selector":"a.text-link","multiple":false,"regex":"","delay":0},{"id":"next","type":"SelectorLink","parentSelectors":["next","debut"],"selector":"#zoneAfficherDetailProfil > div.modal-header > div:nth-child(2) > div > div > button.btn.btn-default.btn-nav","multiple":true,"delay":0},{"id":"debut","type":"SelectorLink","parentSelectors":["_root"],"selector":"#liMiniCv8106265204 > div > div.media-body > h2 > button","multiple":false,"delay":0}]}
Si quelqu’un comprend comment je pourrais changer le code pour arriver à scraper cette page je lui en serais très reconnaissant !
Merci d’avance

 Merci.
Merci. j’ai le meme probleme qu’avec mon script
j’ai le meme probleme qu’avec mon script