Bonjour a tous :
Je suis nouveau parmi vous, je voudrais savoir comment faire pour récupéré juste les adresses mails et non tout les
.
Merci d’avance
Bonjour a tous :
Je suis nouveau parmi vous, je voudrais savoir comment faire pour récupéré juste les adresses mails et non tout les
.
Merci d’avance
Salut !
Tu peux :
OU
Tu pourrais surement aussi utiliser du regex, mais je m’y connais pas. J’utiliserai le split personnellement si le volume de données à traiter n’est pas trop important, ce n’est peut être pas le plus optimisé mais ça marche !
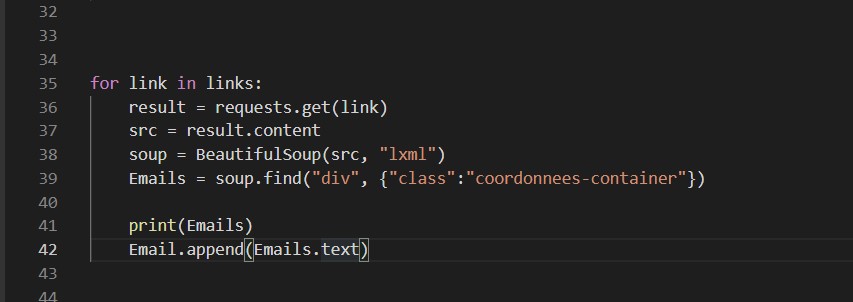
emailDiv = soup.findAll('div',{'class':'coordonnees-container'})
emails = [div.split("mailto:")[1].split('">')[0] for div in emailDiv]
print(emails) devrait te donner un array avec tous les emails
Hello @M.youssef,
Le plus simple est de récupérer directement l’attribut href des balises <a> contenant mailto:
import re
a_list = soup.find_all('a', href=re.compile('mailto:'))
emails = [a['href'].replace('mailto:', '') for a in a_list]