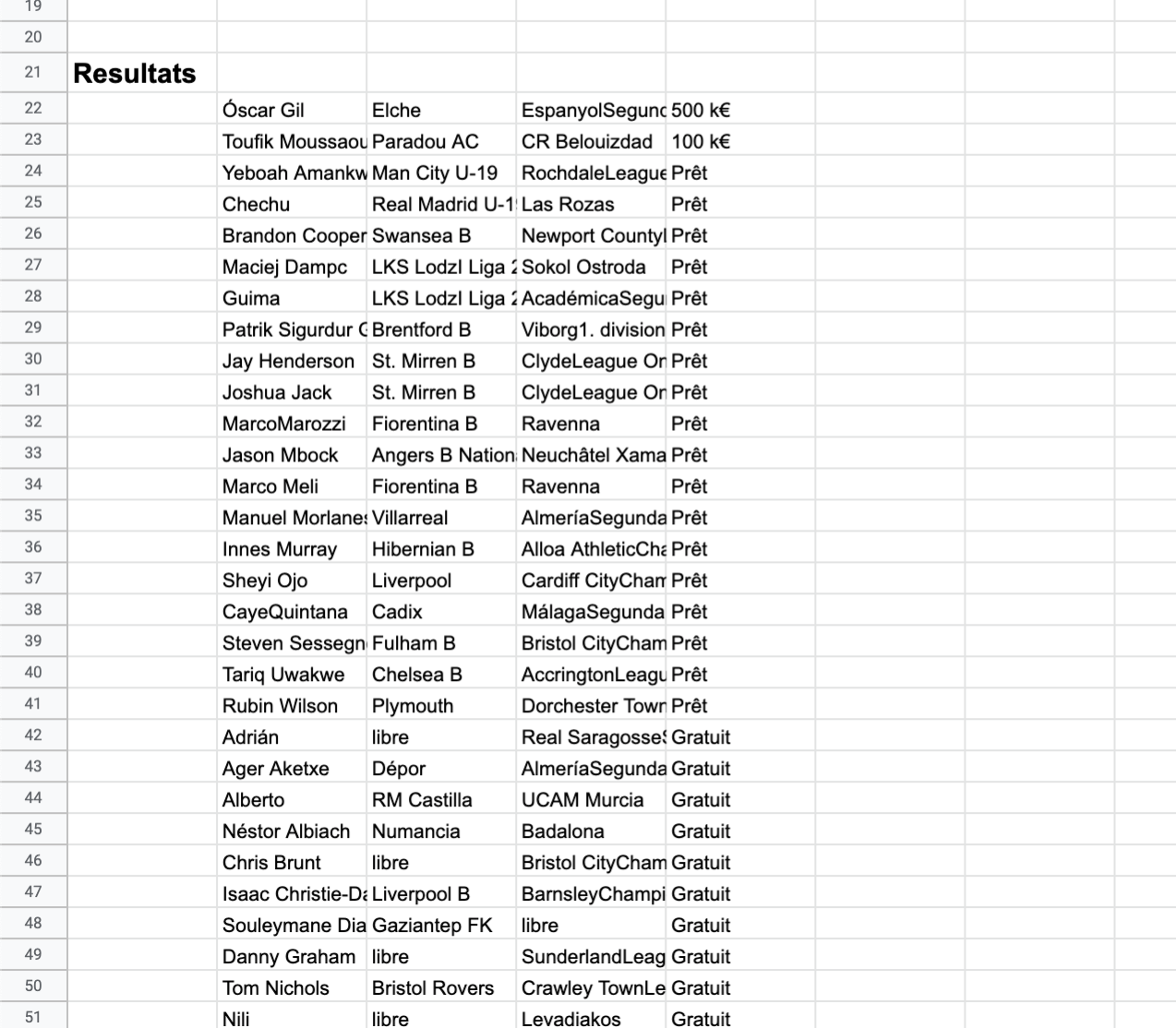
Bonjour à tous,
Je débute en scraping et j’aurais besoin de votre aide.
J’essaye de récupérer des infos sur une page où la pagination est faite en JavaScript :
https://www.footballdatabase.eu/fr/transferts/-/2020-09-07
J’arrive bien à récupérer les infos sur la première page, puis je pagine sur les autres pages avec un SelectorElementClick, mais ça ne me récupère pas les infos.
J’avais réussi à le faire avec ParseHub, mais la version gratuite est limitée à 200 pages et j’en ai parfois plus.
Voilà le sitemap que j’ai créé :
{"_id":"transfers","startUrl":["https://www.footballdatabase.eu/fr/transferts/-/2020-09-07"],"selectors":[{"id":"tab_joueurs","type":"SelectorElement","parentSelectors":["_root","next_page"],"selector":"#count_0_0 div","multiple":true,"delay":0},{"id":"joueur","type":"SelectorText","parentSelectors":["tab_joueurs"],"selector":".name a","multiple":false,"regex":"","delay":0},{"id":"next_page","type":"SelectorElementClick","parentSelectors":["_root","tab_joueurs"],"selector":"#count_0_0 div","multiple":true,"delay":2000,"clickElementSelector":"#pages_1 a.active","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"}]}
Comme je débute, je n’utilise peut-être pas les bons selecteurs, alors toute aide sera la bienvenue.
Merci et A+