Bonjour à tous, je lis ce forum depuis pas mal de temps mais je viens tout juste de franchir le pas pour m’inscrire.
Je n’ai aucune connaissance en développement mais je m’intéresse de prés au scrapping. J’arrive à relativement bien maitriser des outils comme import.io ou scraper, cependant je bloque sur un point.
Les adresses email des avocats y figurent, le problème c’est qu’on y accède en cliquant sur les profils individuels, c’est justement là que mes connaissances atteignent leurs limites. Comment faites-vous dans ce cas ? Existe t-il un outil qui irait chercher les infos en accédant aux fiches ?
Des outils tels que Import.io ou l’extension Scraper restent assez limité dès lors qu’on sort un peu des sentiers battus.
Dans ce type de cas, on peut éventuellement regarder du coté de l’utilisation de l’extension WebScraper, mais cela nécessite des connaissances en sélecteurs CSS, quoi qu’on en dise ça met une certaine barrière pour les débutants. Sans parler de la courbe d’apprentissage de l’outil liée à la philosophie des « sitemaps ».
Le must, c’est évidemment de savoir coder, ça offre davantage de souplesse et permet de s’adapter à n’importe quel cas particuliers.
Hello @Sempiterna, effectivement comme le suggère @ScrapingExpert, coder donne énormément de liberté, mais effectivement ça requiert du temps, et pas mal d’installation en amont…
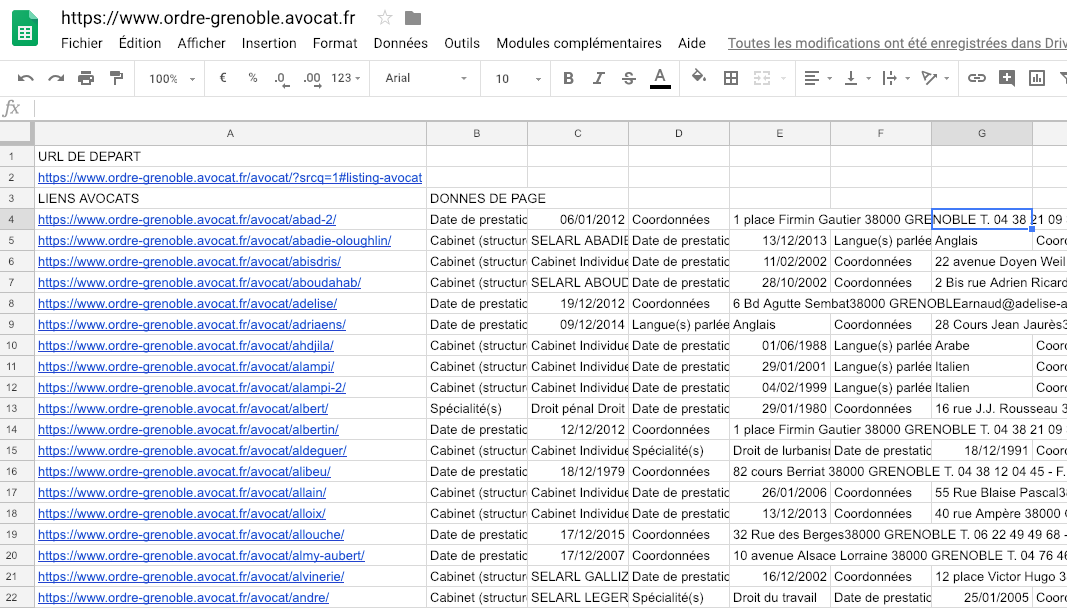
Par contre, sur du petit volume, si tu maitrises le XPath, tu peux faire des merveilles simplement avec un Google Sheet et la fonction IMPORTXML
Bonjour Scraping expert je demarre en Python et suis en train de mettre en place un système automatisé. Je butte sur un problème pour lequel je ne trouve pas de réponse.
Comment organiser ma base de données et également quelle db utiliser: sql nosql, etc?
Saurais-tu me conseiller ?
L’objectif est de pouvoir retranscrir ces données via une api
Constance, si vous ne savez pas comment organiser les données, que ces données ne sont pas encore bien définies ou encore que celles-ci peuvent changer d’un site à un autre, le plus simple (ce qui donne le plus de souplesse) est la base nosql. En python vous pouvez utiliser mongodb. Librairie python « pymongo » pour l’utiliser. https://api.mongodb.com/python/current/
Bonjour Constance, Seb a bien résumé les choses.
Je vous suggère de passer sur une base nosql comme MongoDB, plus flexible car schemaless, pas de contraintes de rajout de colonnes, et plus adapté aux APIs en JSON, de part son format natif en JSON
merci. Je suis en train de regarder, et mongo a l’air de correspondre. Du coup est ce qu’il vaut mieux prendre un hosting avec mongo db ou prendre mongo as a services ?
A vous de voir, si vous ne souhaitez pas vous prendre la tête avec la gestion de l’admin de la DB, avoir quelque chose de clé en main concernant la scalabilité et un modèle distribué sur plusieur shards et réplicas, vous pouvez optez pour du MongoDB as a service (type mlab ou mongodb atlas).
Sinon, si c’est juste pour débuter, avec quelques DBs et collections, sans contraintes particulières sur l’admin ou gestion de db distribuées, il est préférable de rester en local (installer mongodb par vous même sur le serveur dédié, ou l’avoir en natif sur le hosting)
Merci Xavier. Suite à votre 1er message de janvier, j’ai testé l’install en local + commencé à créer des collections, etc. pour comprendre le fonctionnement de Mongo et valider que cela correspondait à mon besoin. Mon projet est de le faire fonctionner avec une api qui sera utilisée par plusieurs front end, dont un bot. As a service dans ce cas me semble le mieux adapté, sauf qu’il y a quelques données sensibles. Côté sécurité, des données, je ne sais pas si c’est très sûr en mode as a service. Mongo Atlas proposant de passer par AWS, Google ou Azure. Qu’en pensez-vous ?
Question sécurité je pense que c’est une non question, au vue des infrastructures mises en oeuvre, et des couches applicatives niveau sécurité/authentification, on est vraiment pas mal Surtout avec du AWS / Azure, Google Cloud, qui me semblent toujours mieux sécurisés que ce qu’on pourrait faire par nous même.
Par contre, l’argument de l’API utilisée par plusieurs dev front end ne doit pas avoir d’implication dans le choix Base de données locale vs Cloud, sachant que quel que soit l’endroit où sera hébergée la DB, la couche API pouvant être déployée sur le même serveur que la DB, ou sur une autre machine, celle-ci sera accessible par tous les devs (d’où l’utilité de l’API accessible via URL).
Le dernier critère a prendre en compte, ça va être le coût. On peut vite monter à du 60-100€ par mois avec des solutions comme MongoDB Atlas.
Merci @ScrapingExpert. j’ai installé mongo db sur un serveur distant. Plus simple pour notre besoin et effectivement moins onereux que la version atlas