Salut tout le monde,
J’aimerais scrapper ce site : ViaTrajectoire accès Particuliers | Site officiel | Orientation en ESMS pour personnes en situation de handicap
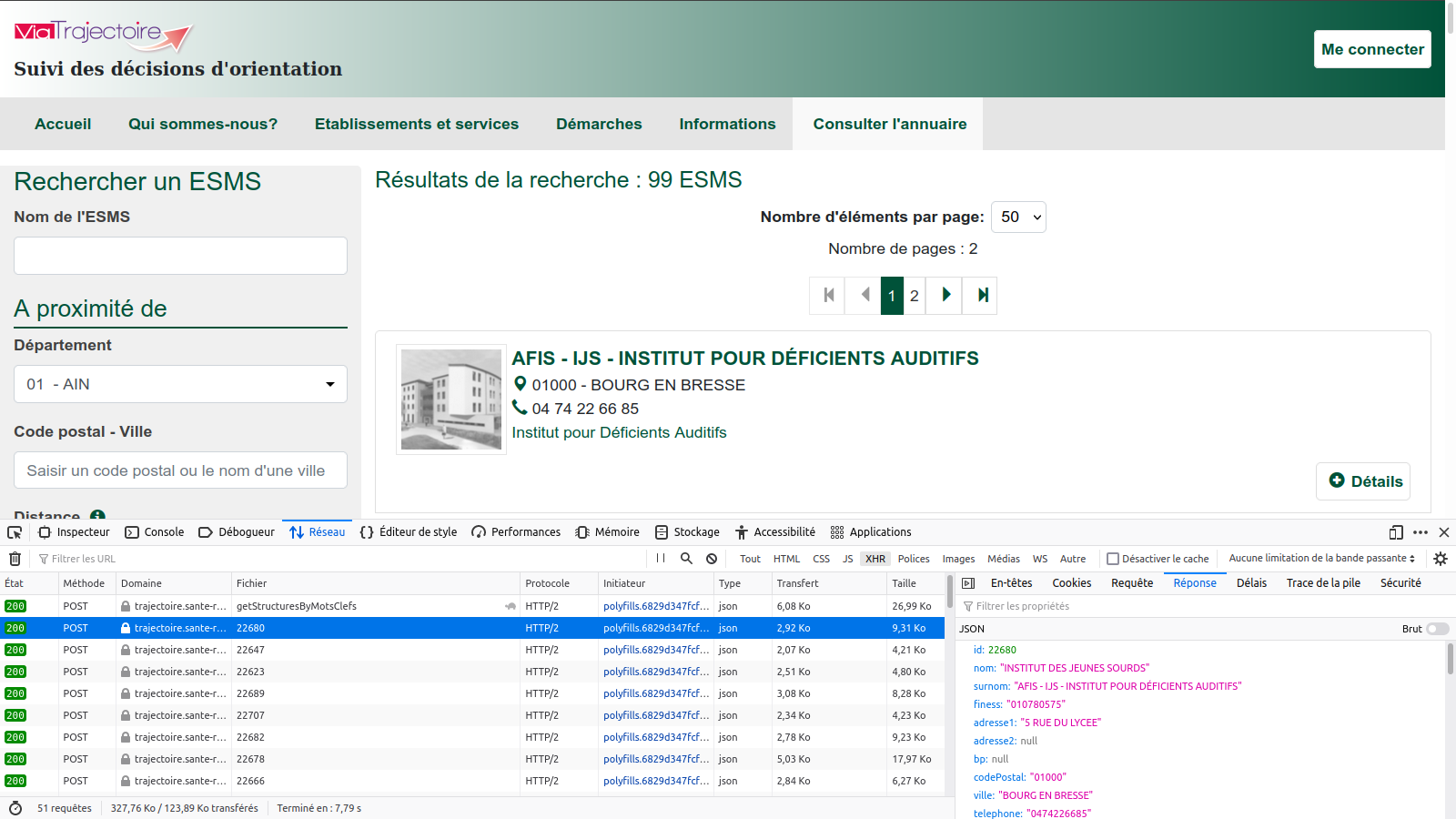
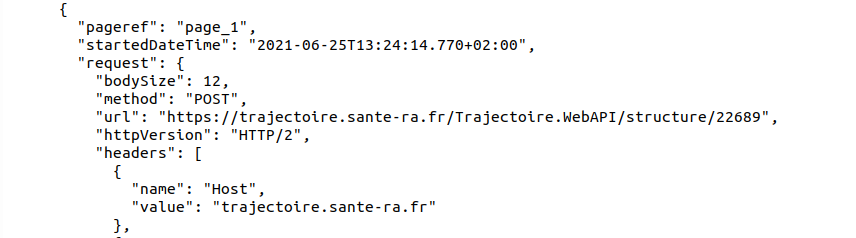
J’arrive bien à scraper les sites statiques avec Web Scraper. Mais là, l’url reste la même quelque soit la recherche. Et je bloque complètement.
Comment feriez-vous pour scrapper ce site ? (en no code si possible ?? )
J’aimerais récupérer :
- la liste de tous les établissements médico-sociaux,
- leur adresse,
- Les informations présentes dans la catégorie « Activités d’accompagnement, de réadaptation ou éducatives » (infos qui se trouvent dans la popup « + Détails »)
- et le nom, l’email et le numéro de téléphone du directeur (infos qui se trouvent dans la popup « + Détails »).
J’espère que certains d’entre vous se sentiront inspirés par ce sujet 
Merci d’avance pour votre aide.
Thomas