Hello,
Je bosse sur un app en ce moment ou j’ai des blocs de texte en entrée et je souhaite avoir un pourcentage de chance que ce texte soit relatif du vocabulaire de cuisine / recette. J’ai essayé plusieurs méthodes mais je me demande est ce que je ne suis pas en train de réinventer la roue.
La méthode que je suis en train d’experimenter implique de constituer une base de donnée de mots liés au vocabulaire de cuisine ( ingrédients, actions, objets etc … dans plusieurs langues ) et de les comparer a chaque mot de mon bloc de texte et definir un score.
Le problème principal de cette méthode (hormis le fait qu’elle soit un peu archaique) est qu’elle nécessite de créer une énorme base de donnée ( ce qui prends enormement de temps meme en scrapant des données ici et la ).
Vous auriez des idées d’approches/méthodes a essayer ?
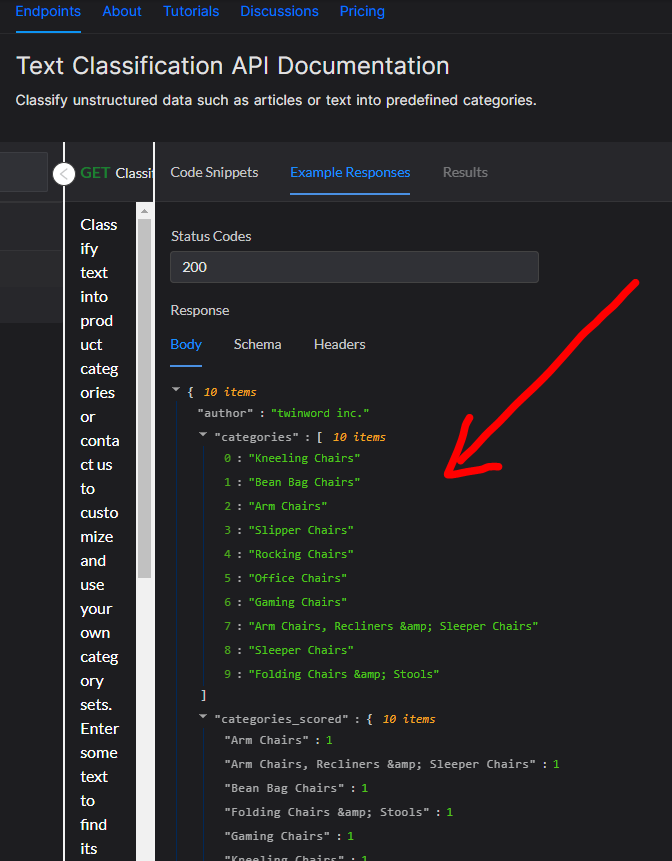
Tu lui donnes du texte et il est capable de te donner des catégories clés qui sont liés au texte.
Avec un score de confiance, 0 étant la valeur la plus faible et 1 la valeur de confiance maximal
Donc par exemple 0,95 étant un indice élevé.
Je pense que ça ne doit pas être le seul service de « Text classification ».
J’avais envie de chercher vite fait si une solution semble exister pour la problématique de @StevenB
Finalement j’ai opté pour pour mon propre model de Machine learning. Je pense que c’est la solution la plus adaptée à mon problème. Si vous avez des questions n’hésitez pas