Hello tout le monde ! J’espère que vous allez bien,
La CVthèque de pole emploi a bien évolué ces dernières années pour réduire le potentiel scraping dessus, de ce fait mes outils sont maintenant obsolètes pour scraper des datas sur pole emploi.
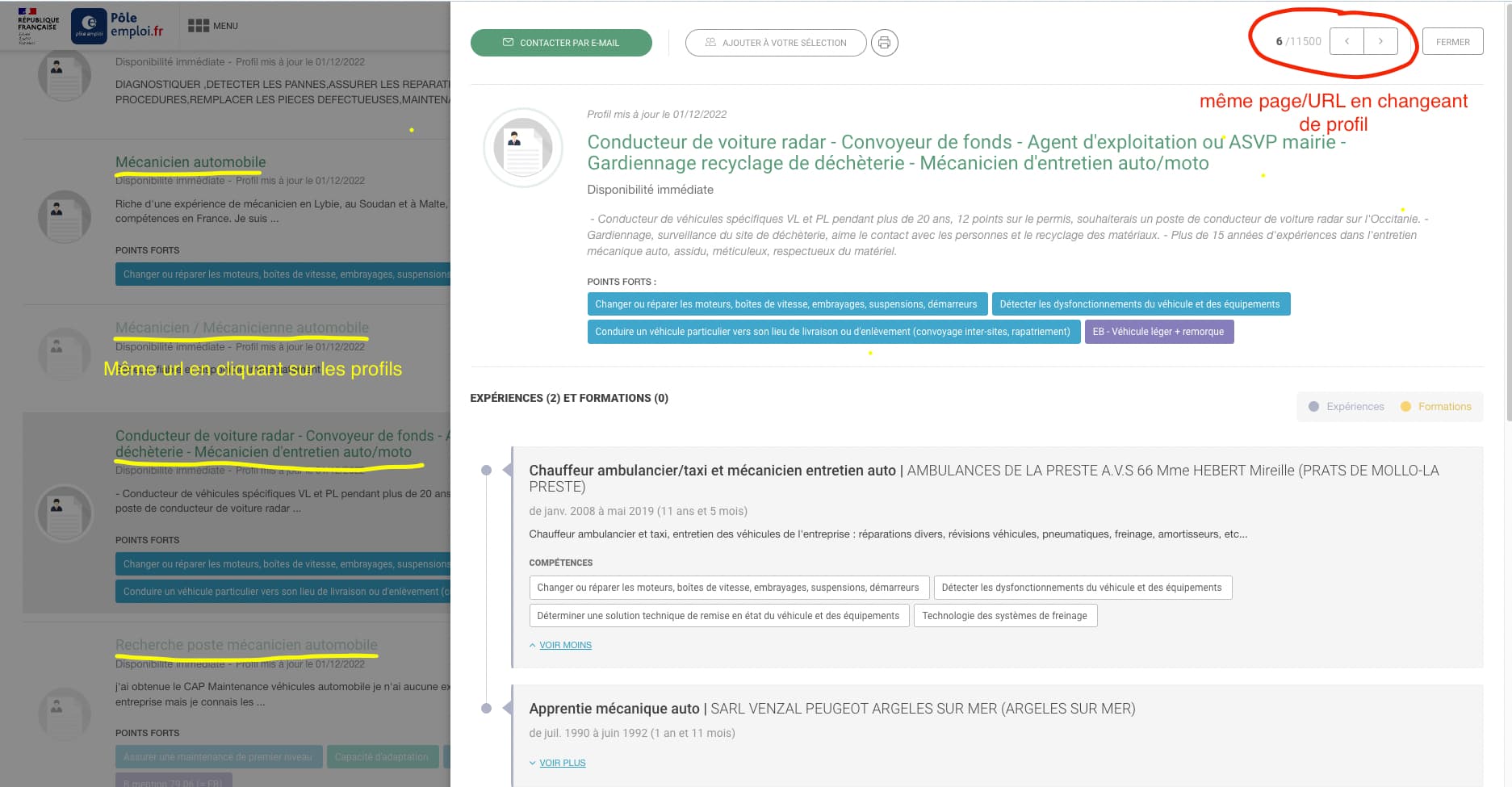
De base comme sur des cvtheque comme hello work je comptais scraper chaque URL de profil, ensuite à partir d’une recipe, crawl scraper toutes ces URLS pour obtenir mes datas.
Mais le problème est le suivant : lorsqu’on clique sur un profil, la page est la même, et la pagination entre les profils fonctionne de sorte à ce que l’on reste sur la même page. (CF image, j’espère illustrer correctement mes propos ahah)
Oui, il s’agit d’un Ajax. Et c’est facilement de gérer les ajax.
et je vous recommande d’essayer octoparse si vous en avez besoin. Ici, c’est un tutoriel pour obtenir les données depuis indeed. Les étapes sont presque les mêmes et Indeed emploie ajax également.
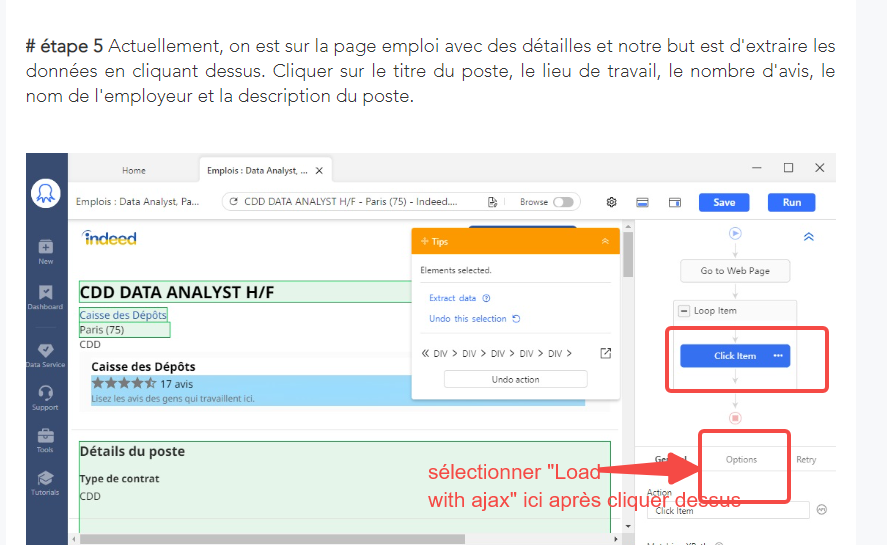
Seulement, cet artilce semble ne pas avoir bien expliqué, et j’ajoute ici : dans l’étape de « clik item », cliquer sur 'Options" et puis « load with ajax », comme ce que montre la capture d’écran.