La semaine dernière, nous avons réalisé un projet intéressant pour l’un de nos clients : une API qui permet d’extraire différentes informations à partir d’une URL en utilisant des expressions régulières. Voici les éléments que nous sommes capables de récupérer :
Adresse e-mail
Numéros de téléphone
Profils LinkedIn
Comptes Twitter
Comptes Instagram
Pages Facebook
Comptes TikTok
Profils Pinterest
Comptes Snapchat
Chaînes YouTube
Forums Reddit
Groupes Telegram
Profils Crunchbase
Cette API est conçue pour faciliter la collecte de données en automatisant le processus de recherche de ces informations sur des pages web spécifiques.
C’est très intéressant. Depuis quelques semaines je m’intéresse à la même idée de base mais via directement une liste d’URL sur Google Sheets avec les fonctionnalités de l’Apps Script. Il y a quelques autres informations qui pourraient être sympa comme la langue du site, meta title, meta description, l’adresse physique, si il y a un bouton « Se Connecter »/« S"inscrire », le nom du CMS du site mais un peu plus compliqué à récupérer avec des RegEx.
Ça pourrait être aussi sympa d’en faire une extension de navigateur qui t’affiche toutes les informations que tu cites, que tu peux facilement venir copier/coller ou tu veux. Ou encore un bouton « Ajouter » lié à une feuille Google Sheets qui t’ajoute une nouvelle ligne sur ton docs avec les infos récupérées.
Nice.
je pense qu’il utilise un paquet de regex, sinon c’est impossible de faire un truc propre pour les tel, sachant qu’il doit gérer tous les types de tel étrangers. Si c’est bien fait c’est un long travaille, gg à lui
Tu geres les cloudflare et autres ?
la rapidité pour crawler 4 millions de site web ? sur un gros serveur ?
Pas de puppeteer?
Possibilité de l’installer chez soit, ou on dépend de ton infra?
Tarots ?
Tu géreras les adresses aussi ?
J’ai dev aussi ma soluce mais pour crawler 4 millions de sites web, avec 2*2 vm a des lieux différents ca prends 10 jours et pour faire de la masse, je perds 5 % des sites protégés environ
On n’a pas de db, c’est du real-time pour le moment. La db viendra si on fait plusieurs millions de req par semaine pour optimiser notre infrastructure!
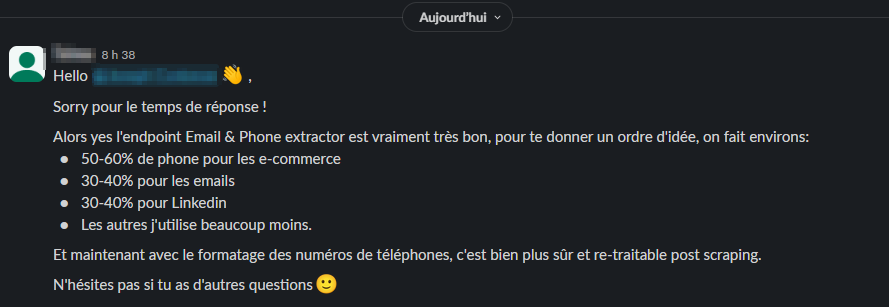
Du coup nous avons significativement amélioré le code source depuis l’année dernière. Maintenant il est possible de spécifier un pays (e.g country_code=FR) pour récupérer un numéro de téléphone, ainsi notre système réalise plusieurs vérifications en cascade interne afin de valider ou non le numéro trouvé sur le site en temps réel. Des entreprises ont intégré notre API avec n8n et leur CRM pour mettre à jour les numéros de téléphone génériques et initier de la prospection, ça fonctionne pas trop mal!