Hey les amis,
J’aimerais retourner l’ID des pages campany Linkedin à partir d’une liste d’URL. Si quelqu’un à une idée (hors blockspring). (cc @ScraperMasters)
Merci d’avance
Hey les amis,
J’aimerais retourner l’ID des pages campany Linkedin à partir d’une liste d’URL. Si quelqu’un à une idée (hors blockspring). (cc @ScraperMasters)
Merci d’avance
je dois louper une info, mais pourquoi tu fais pas juste un site:linkedin.com/company http://deux.io - Google Zoeken ?
edit: si tu veux choper l’ID et non le slug, tu peux ajouter n’importe quoi a l’url et chercher le companyId.
ex: LinkedIn Login, Sign in | LinkedIn
<div class="content js-feed-content"data-has-ds-content="" data-feed-type="company"data-li-sponsor-url=""data-li-sponsor-submission-url=""data-li-add-comment-url="https://www.linkedin.com/company/_internal/mutators/biz_create_comment?companyId=3511687&csrfToken=ajax%3A0321409478587630287&trk="data-li-delete-comment-url="https://www.linkedin.com/lite/remove-comment?csrfToken=ajax%3A0321409478587630287&trk=">
==> 3511687
Yes, c’était mon idée première, mais je me demandais si une personne avait fait un outil via la database company de Linkedin. Car Google est de plus en plus galère à scrapper ces derniers temps. Beaucoup de proxy grillé chez eux, et tu peux avoir un peu de déchet dans le lot.
@camille sinon faut se rendre en mode deco sur la page en question , ensuite dans le code source de la page tu recuperes le JSON qui va bien :
Exemple avec : https://www.linkedin.com/company/orienco-sas
Dans le source tu récupères :
{"specialties":["Dried Fruits and Nuts"],"canSeeShareBox":false,"website":"http://www.orienco.fr","universalName":"orienco-sas","size":"11-50 employés","description":"ORIENCO , specializes in the import., export., processing and distribution of nuts (almonds, pistachios, peanuts, cashew nuts...), as well as exotic and Lebanese products.","isZHCN":false,"embeds":{},"pageInfo":{"isLoggedIn":false,"pageKey":"biz-company-public"},"websiteWithRedirect":"https://www.linkedin.com/redirect?url=http%3A%2F%2Fwww%2Eorienco%2Efr&urlhash=dwpu","isZHTW":false,"isAutocreatedCompany":false,"industry":"Import et export","loginUrl":"https://www.linkedin.com/uas/login?session_redirect=https%3A%2F%2Fwww%2Elinkedin%2Ecom%2Fcompany%2Forienco-sas","companyType":"Société à responsabilité limitée (SRL)","companyName":"ORIENCO SAS","includeSecondAd":true,"jobsSeoUrl":"https://www.linkedin.com/jobs/orienco-sas-emplois","yearFounded":1991,"headquarters":{"city":"Aulnay Sous-Bois","zip":"93600","state":"","street1":"8 Rue Nicolas Robert","country":"France","street2":""},"jobsUrl":"https://www.linkedin.com/jobs/search?f_C=1649172&locationType=Y","showSeeJobsOnTopCard":true,"canSeeProductMarketing":false,"trackingUuid":"qnv4+yGNQ127Myi3NvNg/A==","autogeneratedDisclaimerUrl":"https://linkedin.com/help/linkedin/answer/52989?trk=biz-company-public&lang=fr","homeUrl":"https://www.linkedin.com/company/orienco-sas","legacyLogo":"/p/5/000/1dc/0e1/3b64a71.png","type":"company","joinUrl":"https://www.linkedin.com/start/join","includeTopAd":true,"includeFirstAd":true,"companyId":1649172,"isCJK":false}
Ensuite tu parses le JSON et tu obtiens notamment le companyId:1649172
A noter qu’il faut environ 25 proxies pour 1000000 de fiches avant que les IP soient totalement cramées.
Combien d’entreprises ?
Ok je comprends mieux…en mode api, je n’ai pas, sorry.
@karni t’es trop chaud ![]() J’aime ça
J’aime ça ![]()
J’avais un projet de scrapper toute la base linkedin soit 12 millions de fiches - ça ferait donc 300 proxies… À tester
Je viens de voir qu’ils ont limité les résultats par recherche…arff j’aurais du faire avant.
Tu peux passer par le directory : https://www.linkedin.com/directory/companies/
Sinon tu peux utiliser les urls sous la forme : hxxps://www.linkedin.com/company/1649172 (cf avec exemple d’'ID plus haut).
1/Tu commences à hxxps://www.linkedin.com/company/1000
2/Tu incrémentes l’ID de 1 à chaque nouvelle requête
3/ Tu scrapes le JSON de chaque page
PS: ça risque de prendre un peu de temps ^^.
Bien vu, J’y pensais ![]() En plus comme les ids se suivent, une fois que tu as récupérer le gros lot, tu peux ensuite venir faire des updates pour avoir les suivantes. Pas mal merci.
En plus comme les ids se suivent, une fois que tu as récupérer le gros lot, tu peux ensuite venir faire des updates pour avoir les suivantes. Pas mal merci.
Apparemment, dorénavant, il suffit de récupérer l’URL de redirection obtenue à partir des anciens liens entreprises.
Exemple:
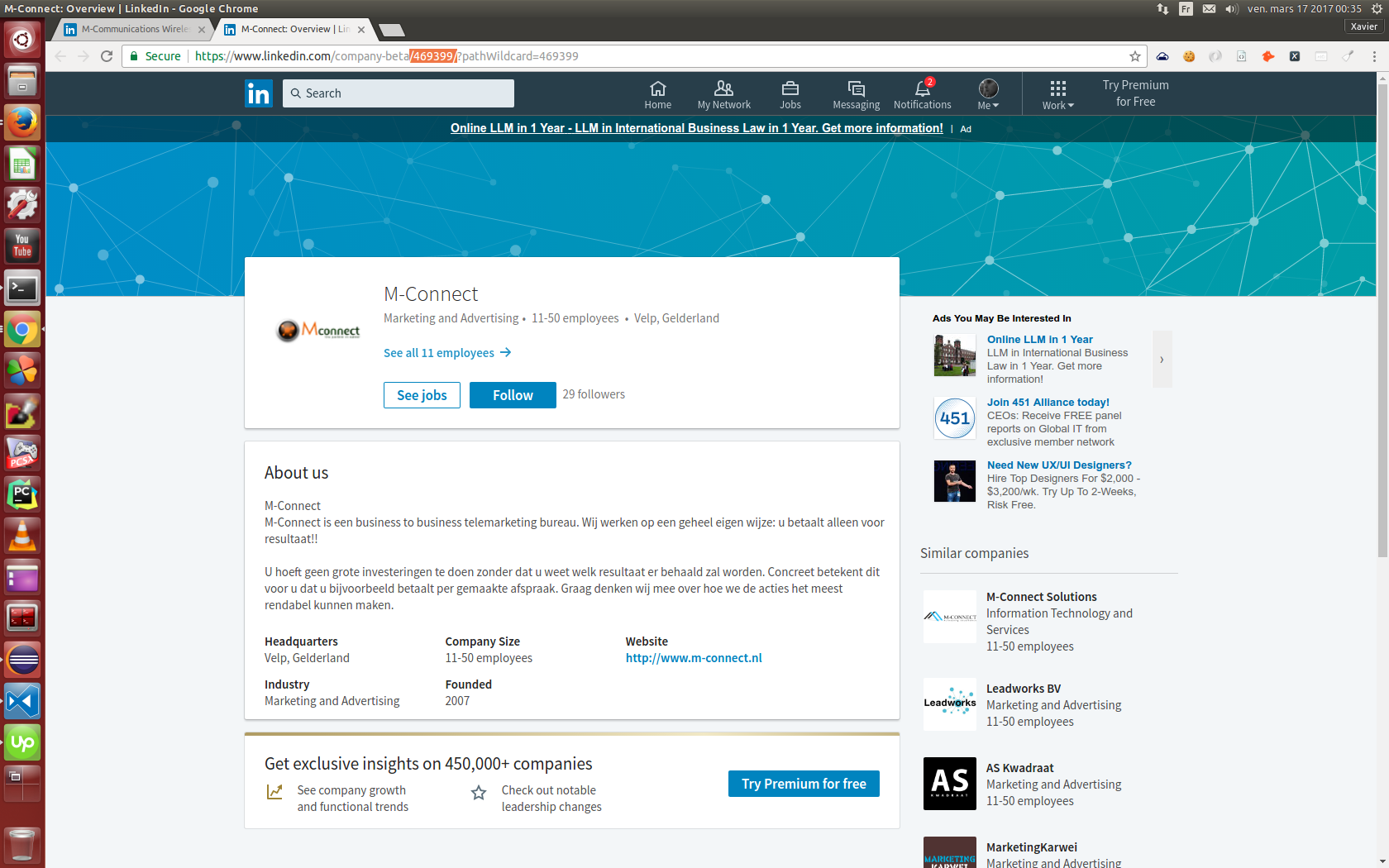
avant: « M-Connect | LinkedIn »
maintenant: « LinkedIn Login, Sign in | LinkedIn »
Ils semblent avoir déployer un nouveau système de routage d’URL « company-beta », du coup quand tu browses l’ancien lien, tu es redirigé sur cette nouvelle URL qui contient directement l’ID que tu recherches.
En gros, avec un bot qui se connecte via ton compte, tu injectes tes urls en entrées et récupères les nouvelles via la redirection, et hop ID trouvés.
Sauf erreur, si tu dois faire çà avec ton compte tu laisses quand même 1 paquet de traces sur du volume …du coup en mode stealth c’est pas genial non ?
Disons qu’ils ne nous laissent plus le choix. Avant on pouvait facilement browser des pages companies en mode offline.
Or maintenant ce n’est plus le cas, on a cette fameuses redirection avec code HTTP 999 vers page d’inscription, via l’algo de protection Sentinel. A moins de pouvoir contourner cette protection avec une multitudes de proxys non black listés, cela me semble difficile.
Pour ce qui est de laisser des traces sur du volume lorsqu’on passe par un compte, il faudrait voir quels volumes sont tolérés et à partir de quand on risque quelque chose.
Je viens de tomber sur https://datafox.com, pas mal…