J’utilise https://www.apify.com/ et en suis très satisfait pour un scraper que j’ai réalisé qui scanne les entrées du bodacc mais impossible de faire fonctionner un autre scraper que j’ai codé pour extraire les résultats des pages jaunes. Le site doit détecter le comportement du browser headless (j’envoie pourtant des en-têtes de browser réel) et bloque le scrap.
Quelqu’un a-t’il contourné les protections des PJ ?
Ca ne va pas vraiment répondre à ta question mais si jamais tu ne trouves pas de méthodes pour scrapper les PJ avec apify, sache qu’il existe Annucapt.
On a beaucoup utiliser l’outil pour aspirer les coordonnées de commerçants et restaurateurs.
Malheureusement, depuis peu, les pages jaunes ne diffusent plus les adresses e-mail sur leur site.
Merci pour ta réponse. En fait, l’adresse email ne m’intéresse pas, le rendement des campagnes par email n’est pas au rendez-vous alors que j’ai un ROI beaucoup plus intéressant avec des techniques mixtes. Les pages jaunes m’intéressent pour leur segmentation et l’analyse de l’environnement concurrentiel des prospects. Je suis surtout intéressé par des scénarii de chaînage de scraping et d’actions pour arriver à contacter les décideurs sur LI ou FB messenger.
Pour le moment c’est la brique PJ > société.com qui m’intéresse
Il y a aussi iqualif (mentionné par un membre de la team GH dans un autre post) avec une possibilité de trial mais moins stable quand on l’a testé, cependant il y a la data de PJ et autres annuaires (et l’outil récupère le SIREN/SIRET). https://www.iqualif.com/
Avec plaisir
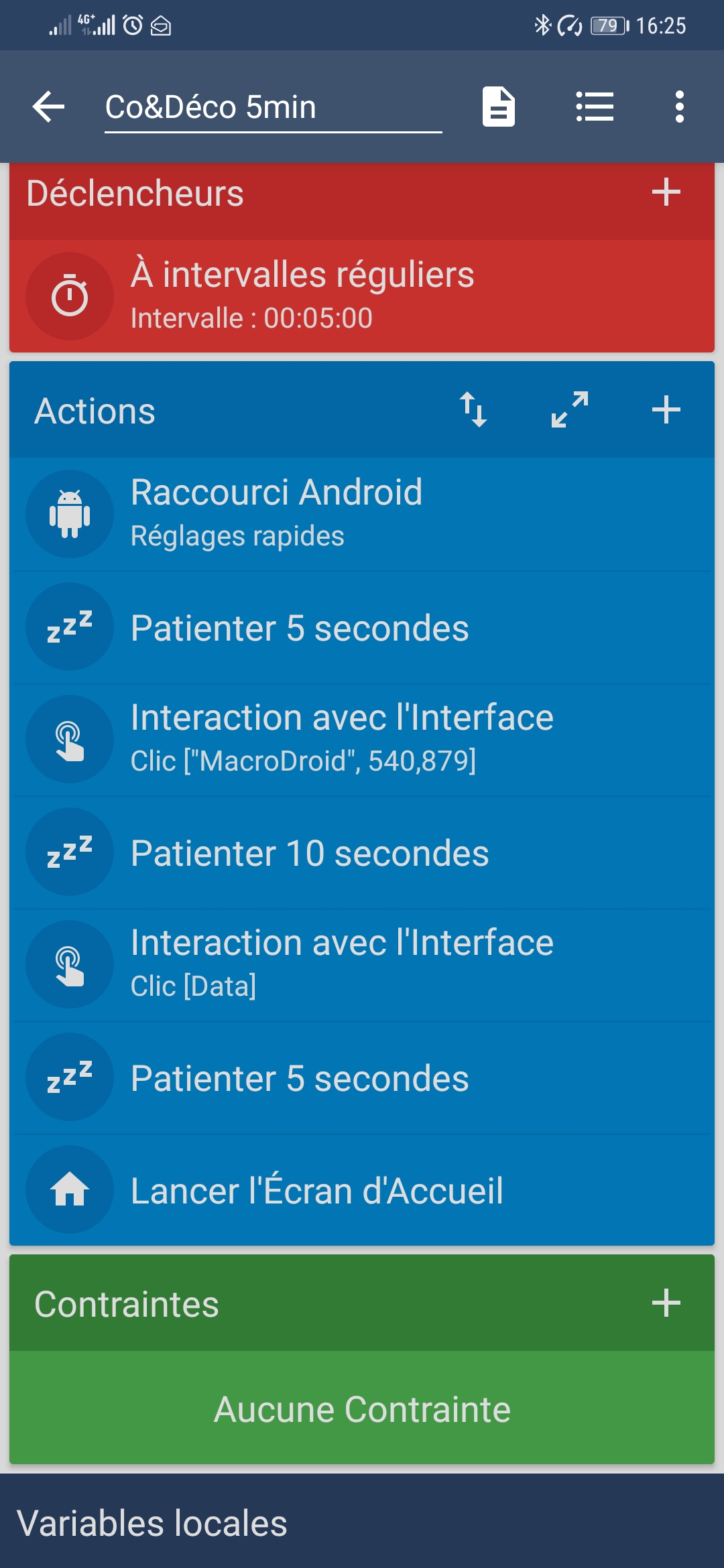
D’ailleurs si tu as des petits besoins, on avait utilisé le réseau 4G d’un téléphone (pour bypass la limitation IP) où l’on avait MacroDroid pour switch ON puis OFF la data en automatique "à l’aide de clics simulés " (sinon il faut root le téléphone), ça a bien fonctionné.