J’ai essayé web sraper, mais en vain…
Avec en plus le nombre de page trop élevé (autopagerize ne marche pas) je commence vraiment à baisser les bras. Avez vous une idée ?
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
import lxml
maxRange = 5
url0 = "http://www.observatoire-ajaccio.fr/quartiers/fiche_association.php?id="
list = []
for k in range(maxRange):
url = url0+str(k)
html = urlopen(url).read()
soup = BeautifulSoup(html, 'lxml')
table = soup.find_all('td')
tmp =""
for l in table:
tmp =tmp +"///"+str(l.get_text())
list.append(tmp)
df = pd.DataFrame(list)
df.to_csv("test.csv")
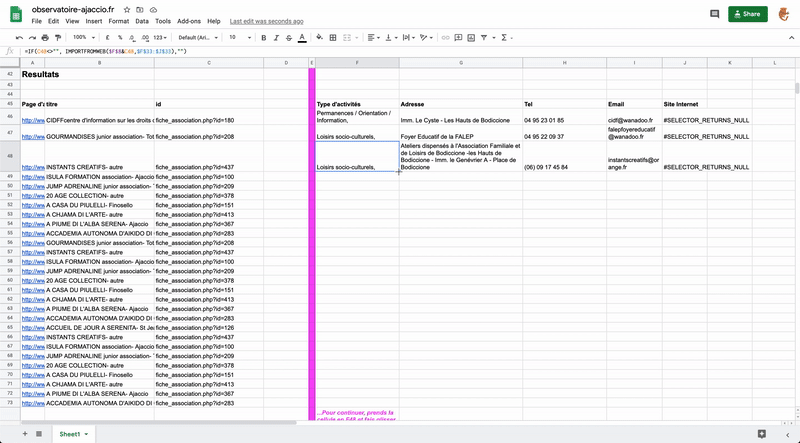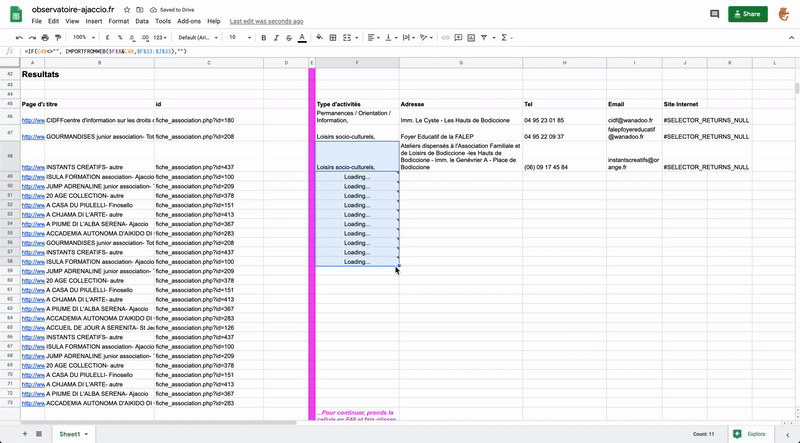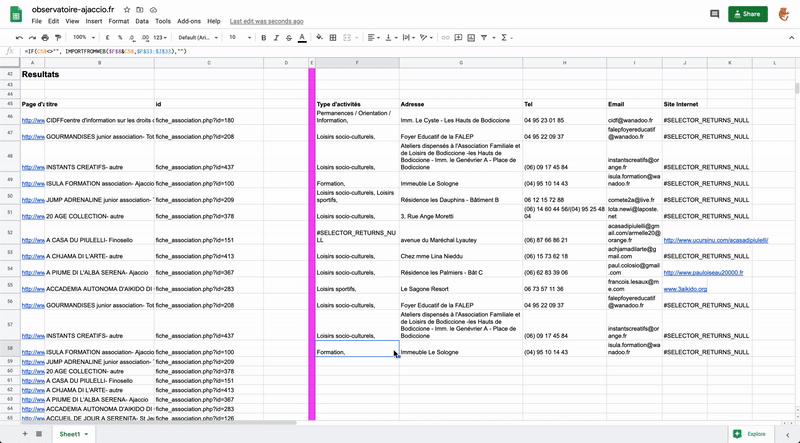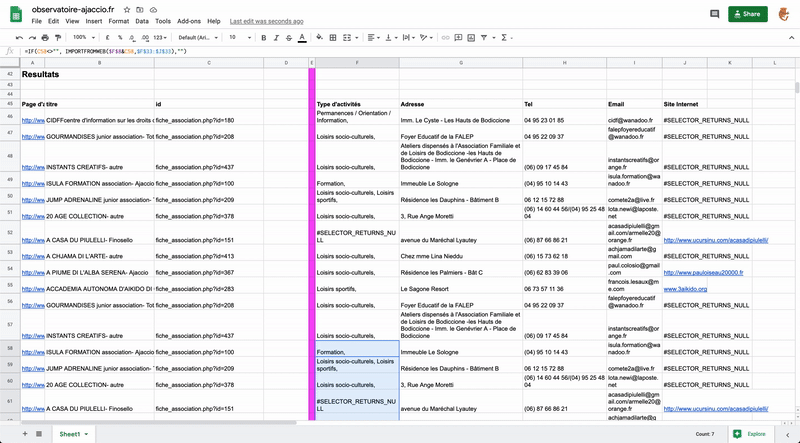
En mettant un max range sur le nombre de pages max que tu veux récupérer tu devrais avoir un csv avec 1 colonne ou 1 ligne par page.
Après tu peux gérer sur excel pour récupérer les emails et les teléphones.