Hello la team de GrowthHacking,
Me voilà confronté à une situation pour le moins embêtante et je souhaiterais avoir votre domaine d’expertise sur le sujet.
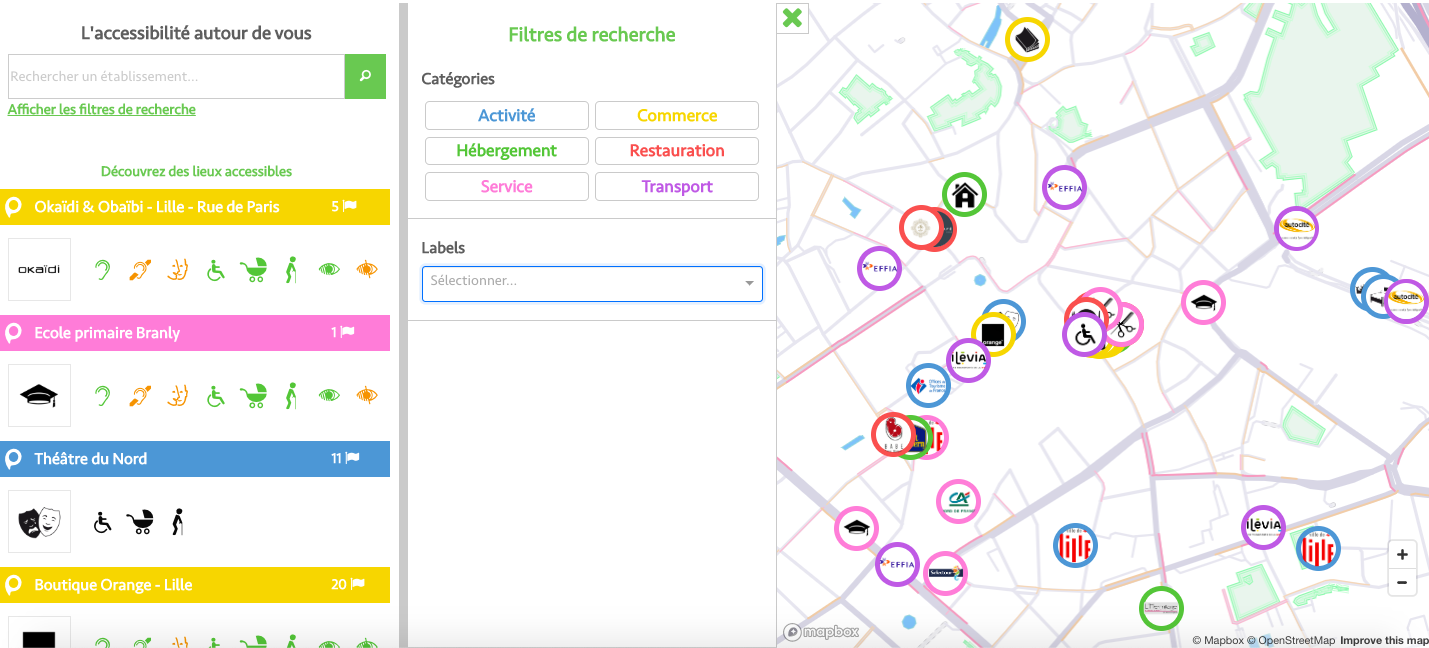
Je souhaiterai scrapper des données d’accessibilités sur un site web qui possède une map comme voici sur l’écran :
Les données à scrapper serait celle-ci :
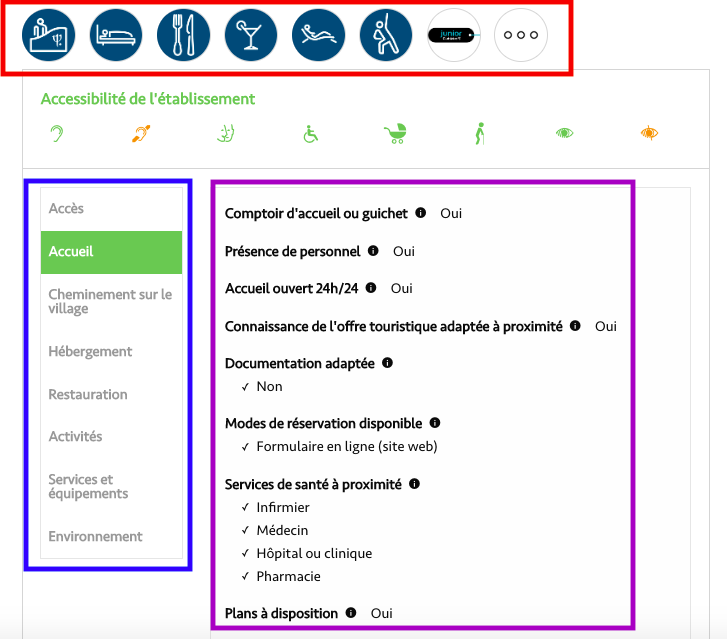
Les données à scraper seraient toutes les informations liées à l’accessibilité de tous les pictos ( encadré rouge ) concernant tout les titres ( encadrés bleu ) avec toutes les infos de chaque titre ( encadré violet). Je ne sais pas si c’est bien clair, mais chaque picto (rouge) possède des titres différents ( bleu) qui contient des données différentes (violet)…
Le tout pour toute la cartographie de France, à savoir que certains des lieu indiqués sur la map ne dispose pas d’info liée à cette accessibilité ce qui laisserait un champ vide ( donc pas problématique)
Pouviez-vous me dire si vous avez des pistes ou des idées pour scrapper cette map de France liée à l’accessibilité ?
Merci bien
Hello David,
Avec un lien du site et liens des pages concernées, ça permettrait de mieux te répondre 
Yes, tout à fait, je transmets ça de suite.
Voici, la map en question :
Un exemple de fiche qui contient des infos d’accessibilités :
https://www.pictoaccess.fr/cards/club-med-vittel-le-parc
Pour réussir ce scraping, il faut le faire en deux étapes:
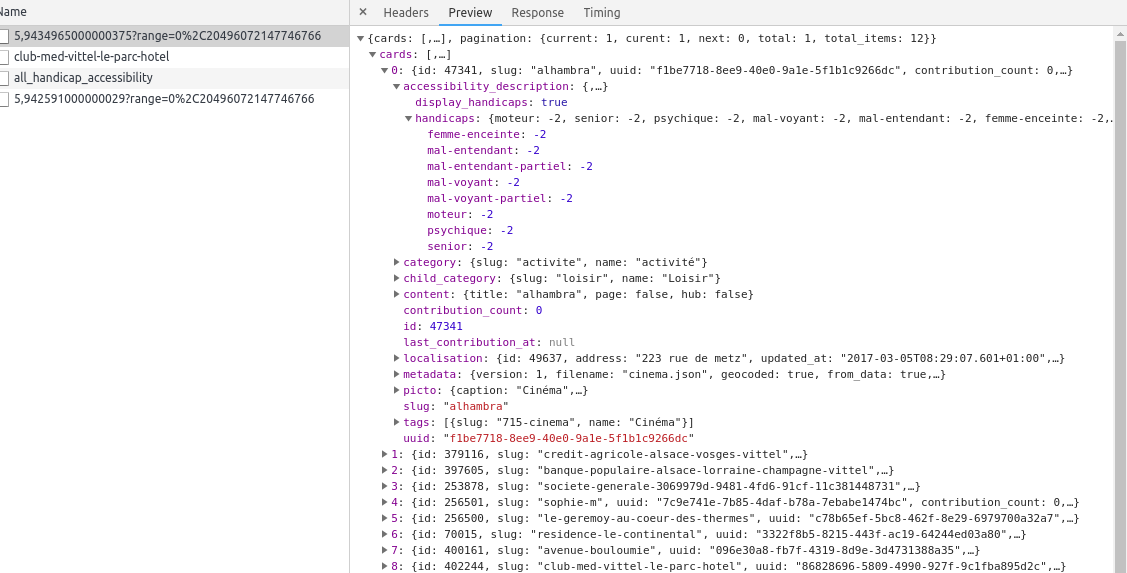
- Extraction des urls de chaque lieu: afin d’obtenir la liste la plus complète des lieux en France, il faut faire varier les paramètres correspondant aux coordonnées géographiques dans l’appel à l’API de recherche de lieux par proximité géographique:
https://api.pictoaccess.fr/cards/nearest/48,86363293424483/2,3511136181958188?range=26%2C235152216432283
Pour cela, il faudrait une base de latitudes/longitudes à cibler, ou faire varier le diamètre du cercle de recherche via la valeur du paramètre « range »
Le JSON résultant nous donne ce type d’informations:
- Extraction des données d’accessibilité
A partir de l’URL de chaque page détail lieu, extraire les informations d’accessibilité souhaitées.
Etant donné la forte volumétrie de requêtes à effectuer et de pages à partir desquelles récupérer des informations, il serait préférable d’envisager une solution 100% automatisée de type script , avec stockage des informations dans une base de données (format JSON de préférence).
2 « J'aime »
@ScrapingExpert excellente analyse. Par contre la valeur du paramètre « range » peut être très haute (2 000 km par exemple) ce qui de fait retourne un très grand nombre de résultats dans le json (‹ total ›: 7800, ‹ total_items ›: 311963).
Du coup on peut itérer simplement en changeant le numéro de page et pas forcément la position géo.
1 « J'aime »
Tout à fait, c’est ce que j’avais commencé à dire dans mon propos en mentionnant le fait de prendre un range plus important, mais en oubliant de parler du paramètre de pagination.
Merci d’avoir pointer cet oubli
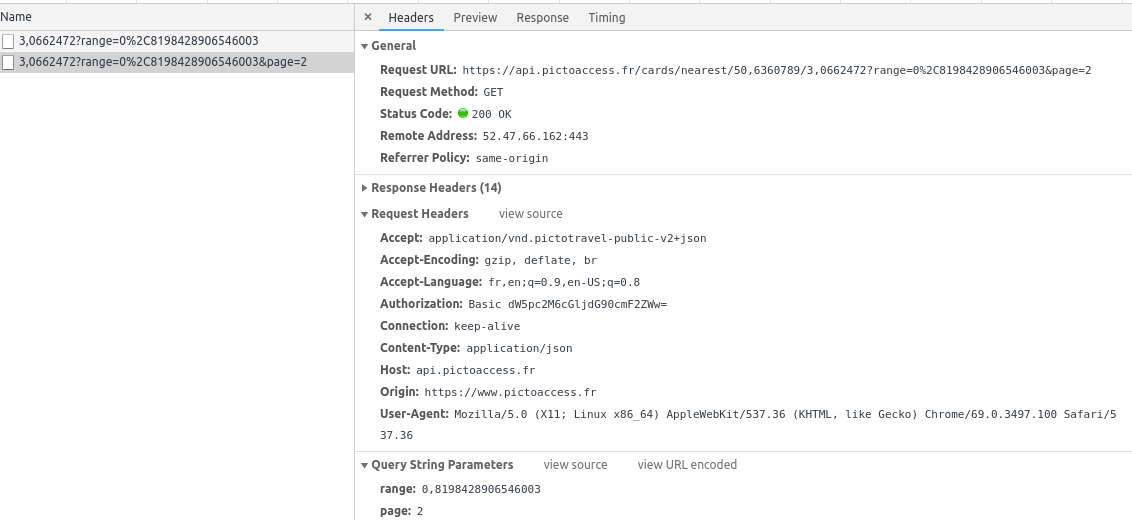
Sans oublier que les requêtes sur leur API, sont de type « GET » mais nécessitent un token d’autorisation, à placer dans le header « Authorization »:
2 « J'aime »
Merci pour vos réponses très pertinentes, je vais y consacrer mon après midi pour voir ce que ça donne.
Je vous communique rapidement des résultats obtenus.