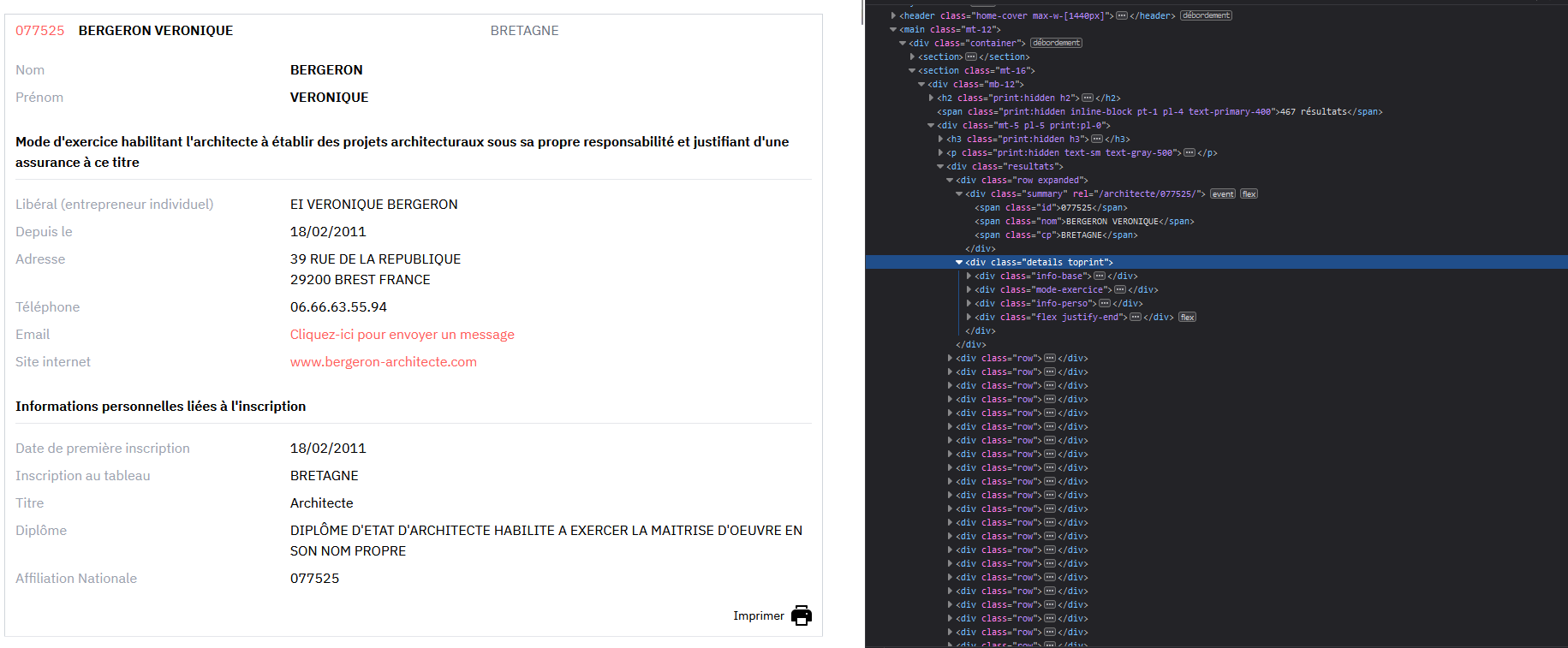
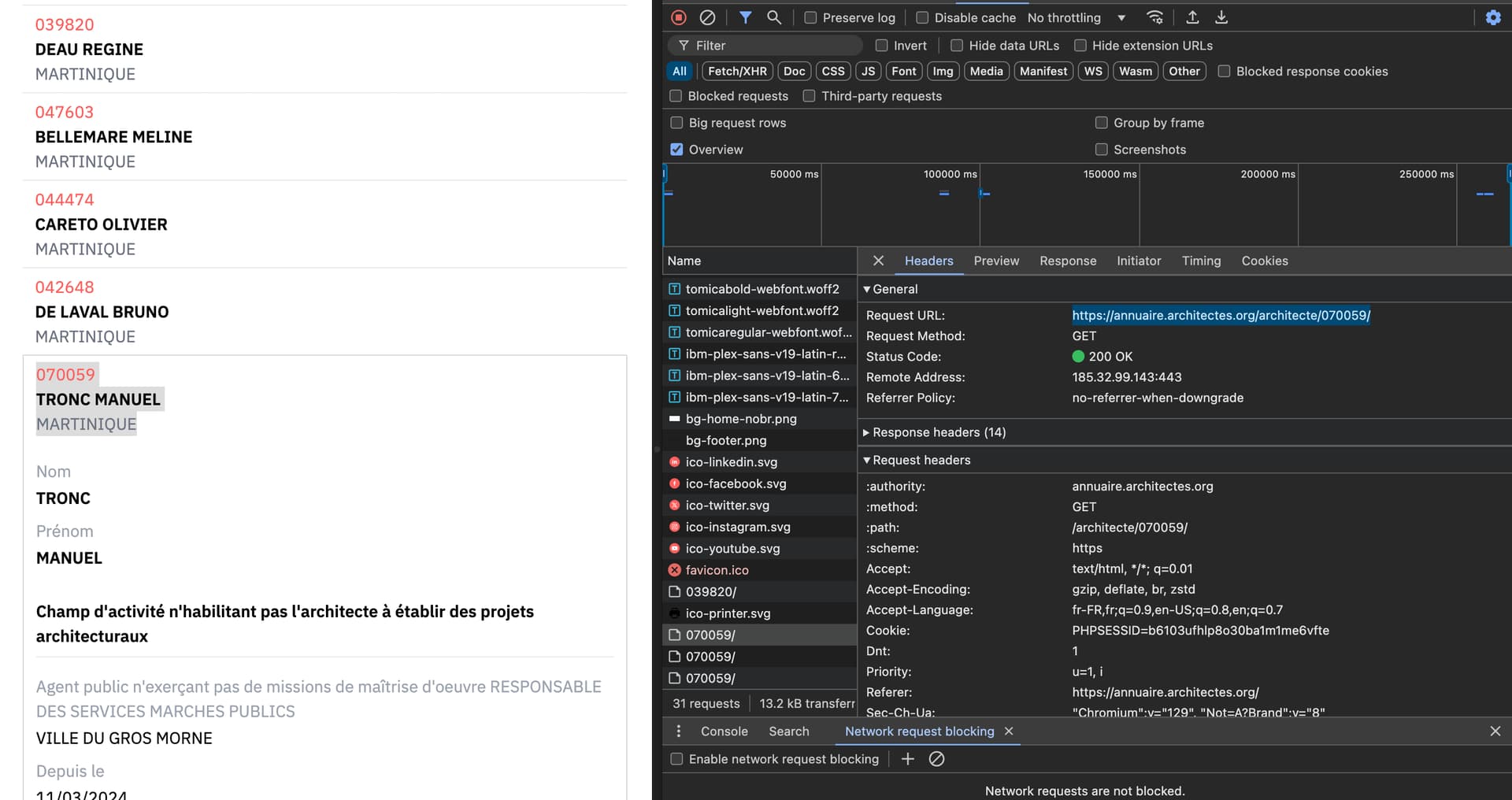
Hello,
Ton site fonctionne avec des requête POST, qui ne demandent pas de paramètre dans l’url pour afficher les résultats (à la différence du get).
Donc à chaque fois que tu sélectionne une région, ton ordi va envoyer une requête post à leur serveur avec ce qu’on appelle un ‹ payload ›, qui identifiera ce que tu as demandé.
Le payload dans la requête POST, c’est l’équivalent des paramètres url de la requête GET (pour faire simple).
Dans ton cas, quand je recherche une région (par ex la Bretagne), j’envoie un payload incluant la valeur ‹ Bretagne ›. En python ca donne :
import requests
url = 'https://annuaire.architectes.org/'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'max-age=0',
'Content-Type': 'application/x-www-form-urlencoded',
'DNT': '1',
'Origin': 'https://annuaire.architectes.org',
'Referer': 'https://annuaire.architectes.org/',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'
}
payload = {
'type': 'non_habilite',
'posted': '1',
'nom': '',
'prenom': '',
'cp': '',
'ville': '',
'code_region': '103', ## Code Région de la Bretagne
'submit': 'Rechercher'
}
response = requests.post(url, headers=headers, data=payload)
print(response.text) ## html de la réponse, avec les prénoms/noms de tes archi
Il te suffit de parser la réponse html de cette requête pour sortir tous les architectes bretons.
Si on va plus loin (autant aller plus loin), tu vois dans le code source de la page les codes région de chacune des régions :
select id="edit-region--2" name="code_region" class="form-select">
<option value="">- Toutes les régions -</option>
<option value="101" >AUVERGNE-RHÔNE-ALPES</option>
<option value="102" >BOURGOGNE-FRANCHE-COMTÉ</option>
<option value="103" selected>BRETAGNE</option>
<option value="104" >CENTRE-VAL DE LOIRE</option>
<option value="105" >CORSE</option>
<option value="106" >GRAND EST</option>
<option value="107" >GUADELOUPE</option>
<option value="108" >GUYANE</option>
<option value="109" >HAUTS-DE-FRANCE</option>
<option value="110" >ILE-DE-FRANCE</option>
<option value="111" >MARTINIQUE</option>
<option value="112" >NORMANDIE</option>
<option value="113" >NOUVELLE-AQUITAINE</option>
<option value="114" >OCCITANIE</option>
<option value="115" >PAYS-DE-LA-LOIRE</option>
<option value="116" >PROVENCE-ALPES-COTE-D'AZUR</option>
<option value="117" >REUNION-MAYOTTE</option>
</select>
Tu rajoutes une loop à ton premier code, pour faire chacune des région :
import requests
url = 'https://annuaire.architectes.org/'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7',
'Cache-Control': 'max-age=0',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'PHPSESSID=b6103ufhlp8o30ba1m1me6vfte', ## Pas forcément besoin
'Origin': 'https://annuaire.architectes.org',
'Referer': 'https://annuaire.architectes.org/',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'
}
code_regions = [
"101", "102", "103", "104", "105", "106", "107", "108", "109",
"110", "111", "112", "113", "114", "115", "116", "117"
]
for code_region in code_regions:
data = {
'type': 'non_habilite',
'posted': '1',
'nom': '',
'prenom': '',
'cp': '',
'ville': '',
'code_region': code_region,
'submit': 'Rechercher'
}
response = requests.post(url, headers=headers, data=data)
## Rajouter ton code de Parsing
Dis moi si c’est compréhensible !