Bonjour à tous 
Bon tout est dans le titre mais voilà, j’ai beaucoup d’URL Linkedin et j’aimerais obtenir le nom de l’entreprise de chaque URL, scrapping assez simple sur webscrapper et ça marche mais le prbl est que je dois rajouter manuellement chaque URL pour refaire le scrap. C’est assez long, quelqu’un a une idée ?
Merci
Salut Frédéric,
Je suis pas expert en scrapping mais si j’ai bien compris je crois que j’ai rencontré la même problématique.
Ma solution artisanale :
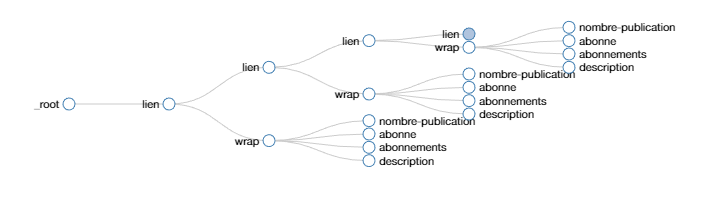
Tu copies / colles l’ensemble de tes urls sur une page web provisoire et tu indiques cette page web comme start url sur webscrapping. Ensuite tu explores chaque lien avec webscrapping comme si c’était de la pagination et tu récupères ton contenu de ce lien.
Dans l’idée :
Je sais pas si je suis bien clair ?
Tu pourrais faire la même chose avec gsheet et l’import xml aussi.
Olivier
4 « J'aime »
Il faut faire un « import sitemap » :
Comment créer un sitemap ?
Pour cela tu exporte le sitemap de template actuelle (pas la version csv) qui va te servir de base et tu rajoutes l’ensemble de tes liens dans ce sitemap (demande si tu galère à formater les urls en url,url,url…) et tu importe ce nouveau sitemap.
EX :
{"_id":"linkedincompany","startUrl":["https://www.linkedin.com/company/thefamily/","https://www.linkedin.com/company/ethereum/,« URL »,« URL »,« URL »…ETC…"],"selectors":[{"id":"name","type":"SelectorText","parentSelectors":["_root"],"selector":".org-top-card-summary__title span","multiple":false,"regex":"","delay":0}]}
3 « J'aime »
Le process indiqué par Camille est pas mal, ça t’évite de passer par une page HTML intermédiaire qui contient tous tes liens de départ.
- Tu export ton sitemap (copié collé du JSON)
- Dans un éditeur de texte, type Notepad++, tu modifies le contenu associé à la clé
startUrl, en rajoutant à la liste JSON toutes tes URLs telle que:
"startUrl":["https://www.linkedin.com/company/thefamily/", "https://www.linkedin.com/company/azertyu" , "https://www.linkedin.com/company/azertyu", "https://www.linkedin.com/company/azertyu", "https://www.linkedin.com/company/azertyu", ... ]
- Puis tu copies ce nouveau JSON édité dans ton presse-papier
- Enfin tu créé un nouveau scénario WebScraper via l’option « Import Sitemap », et tu colles ton nouveau JSON
5 « J'aime »
Je rejoins les différentes réponses déjà évoquées :
- Tu créer son sitemap avec webscraper sur ta page type que tu souhaite scrapper
- Tu exporte le sitemap dans un google sheet
- Pour créer les URL simplement = go concaténation
- Pour la concaténation :
colonne A : "
colonne B : URL obtenues
colonne C : ",
=CONCATENER(A1;B1;C1)
(à la dernière URL transformée pense à virer la virgule)
prends ce résultat copie colle en valeurs les résultats dans une colonne à coté, on va dire que c’est la cellule Z
créer une autre feuille pour une 2e concaténation :
colonne gauche = {« _id »:« linkedincompany »,« startUrl »:[
colonne milieu = ta cellule Z
colonne droite = ],« selectors »:[{« id »:« name »,« type »:« SelectorText »,« parentSelectors »:[« _root »],« selector »:« .org-top-card-summary__title span »,« multiple »:false,« regex »:« »,« delay »:0}]}
Normalement tu a un sitemap en JSON à copier coller lorsque tu feras « import sitemap »
Clair pour toi ?
3 « J'aime »
Merci à tous d’avoir répondu ! J’ai bien réussi grâce à vous de scrapper plusieurs URL mais je pense que les URL Linkedin sont protégés car vos techniques marches pour d’autres sites mais pas celui là. Voici le JSON que j’ai utilisé :
{« _id »:« efedsvd »,« startUrl »:[« https://www.linkedin.com/in/golfieri-guillaume-5ab89b6a/ »,« https://www.linkedin.com/in/tracy-willis-0a698477/ »,« https://www.linkedin.com/in/annelisemasson/ »,« https://www.linkedin.com/in/samantha-marciszewer/ »],« selectors »:[{« id »:« element »,« type »:« SelectorElement »,« parentSelectors »:[« element »],« selector »:« li#\31 003953828 »,« multiple »:true,« delay »:0},{« id »:« Element »,« type »:« SelectorElement »,« parentSelectors »:[« _root »],« selector »:« li#\31 003953828 »,« multiple »:true,« delay »:0},{« id »:« compay »,« type »:« SelectorText »,« parentSelectors »:[« Element »],« selector »:« span.pv-entity__secondary-title »,« multiple »:false,« regex »:« »,« delay »:0},{« id »:« company 2 »,« type »:« SelectorText »,« parentSelectors »:[« Element »],« selector »:« h3 »,« multiple »:false,« regex »:« »,« delay »:0}]}
Sur quelle protection es tu tombé?
Je pense que c’est dans le « selector », Linkedin prend des balises uniques avec un chiffre par profil même si la balise est la même, ça fait « xxx3290" » pour un autre « xxx4390 » par exemple, du coup webscraper est perdu
C’est probablement juste ton sélecteur qui n’est pas bon alors Tu peux écrire des sélecteurs qui cible des attributs qui commencent par xxxx
@Frederic_Duhirel: Peux-tu nous transmettre l’export JSON de ta config (sitemap) ?
Merci, les 2 réponses sont tops et peuvent servir à différentes situations. Je préfère tout de même la version JSON.