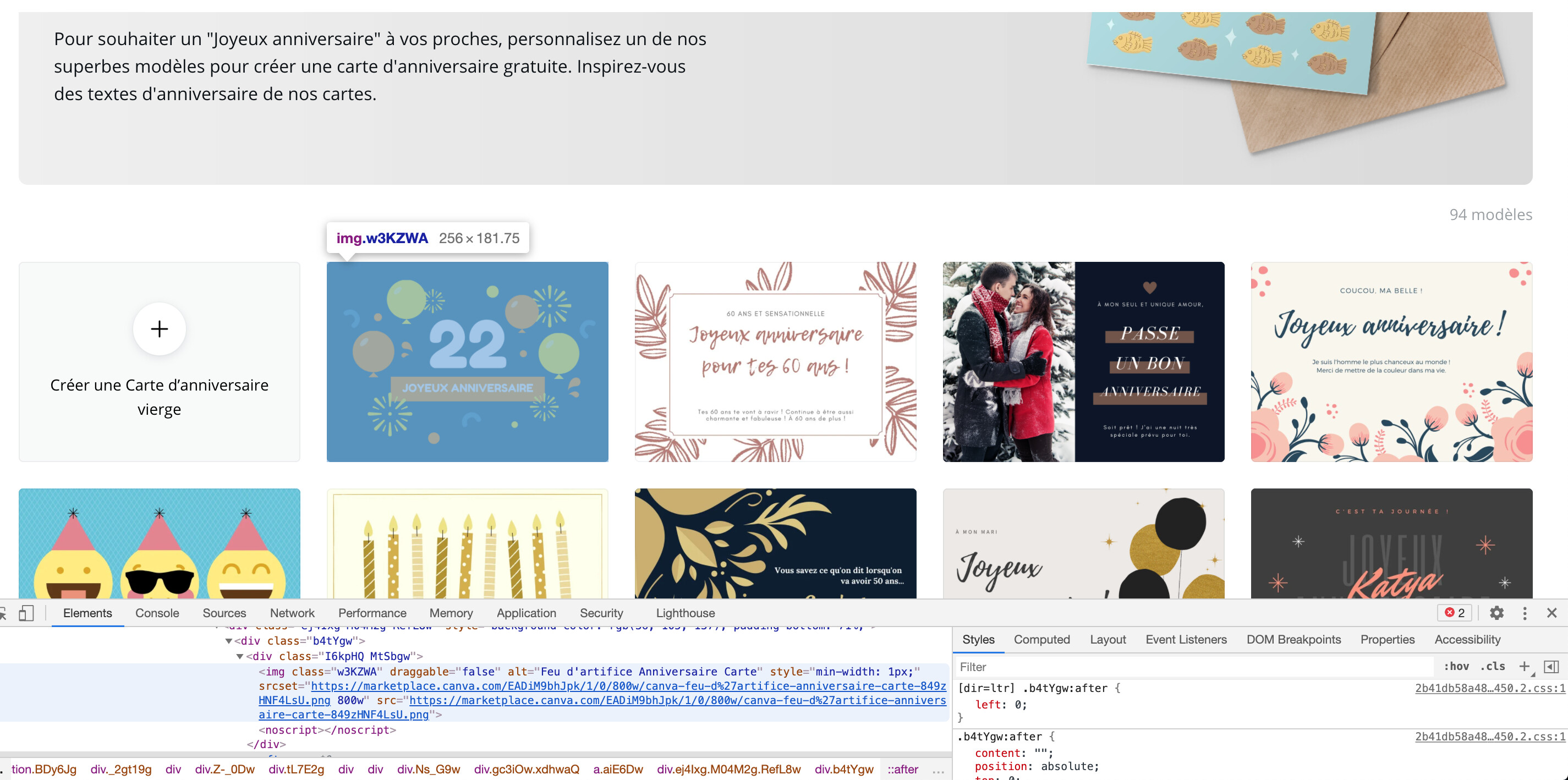
Je ne suis pas un expert scraping donc pour l’instant j’ai seulement essayé via GoogleSheet IMPORTXML et via Parsehub sans succès, je sors une centaine d’url duppliquées = 10 uniques.
Le soucis c’est que Canva utilise cette fameuse technique de class CSS complexe pour chaque div de « carte ».
Une idée de comment contourner ce genre de protection?
Top !
Je n’ai pas trouvé comment sortir les infos directement sur un google sheet, à la limite si tu codes un peu tu pourrais créer une fonction dans google sheet et ça te permettrait d’extraire rapidement les infos.
Sinon tu peux run cette fonction dans la console de ton chrome et copier coller le résultat : document.querySelectorAll(".w3KZWA").forEach(el=> console.log(el.alt, " ", el.src)), ça te sortira la liste ce que tu veux.
Pour info toutes les balises img que tu souhaites scraper ont comme classe « w3KZWA ».
J’espère que cela t’aidera, si tu as d’autres questions n’hésite pas !
J’ai un projet de scraper des images sur un autre site.
Je n’ai jamais essayé de le faire auparavant, mais cela ne semble pas trop difficile d’après cet article comment créer un web scraper d’images sans coder? Donc Je vais essayer mon vieil ami Octoparse et le webscraper mentionné dans les réponses Merci!!