J’ai une question technique : j’aimerais savoir comment faites-vous pour gérer les filtres pour scrapper des pages. C’est toujours face à cette difficulté que je me retrouve bloquée. Que ce soit en python, avec Octoparse ou webscraper.
Tout dépend de la manière dont fonctionne le « moteur de recherche ».
Les filtres se retrouvent quelques fois dans l’url, quelques fois dans les paramètres POST et d’autres fois dans les cookies par exemple…
Vous souhaitez obtenir les info des agences immobilières selon les villes, c’est les villes que vous voulez filtre ? Si oui, c’est facile, utiliser justement l’url et commencer votre scraping.
Dance ce cas précis, les filtres sont en quelque sorte cachés, il n’y a pas de listes de choix sur laquelle se baser. Une solution serait de se baser sur le sitemap du site, encore faut-il le trouver.
Dans ton cas, je ferais à la main les différentes régions pour avoir les url de base, et ensuite le scrap de toutes les page pour chacune.
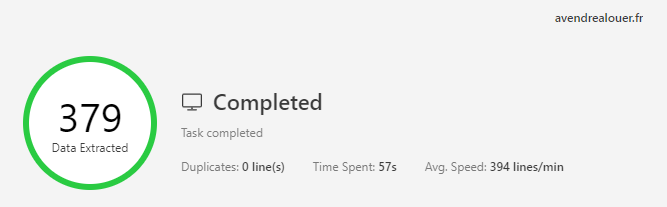
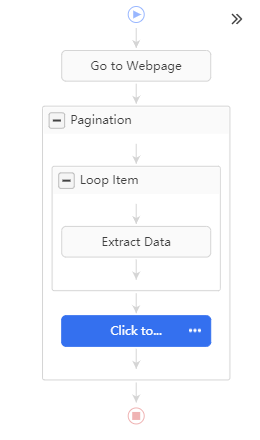
Vous utilisez encore octoparse ? J’ai fait avec octoparse et je ne me vois bloqué par la page 1. Voilà mon workflow, et pour le bouton de pagination, le xpath est //*[@id=« pager-next »]/a . Si vous réessayez ?
Cela m’arrive également que la détection auto bloque à 84%. Et je réessaie en le faisant manuellement, j’y parviens !
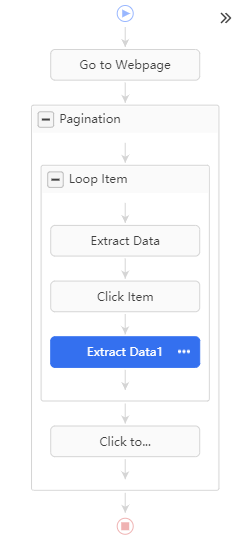
Créer tout d’abord une boucle pour extraire les URLs même si les textes ne sont pas bien détectés.
Récupérer les informations détaillées dans la page de détails.
Voilà mon flux de travail :