Bonsoir,
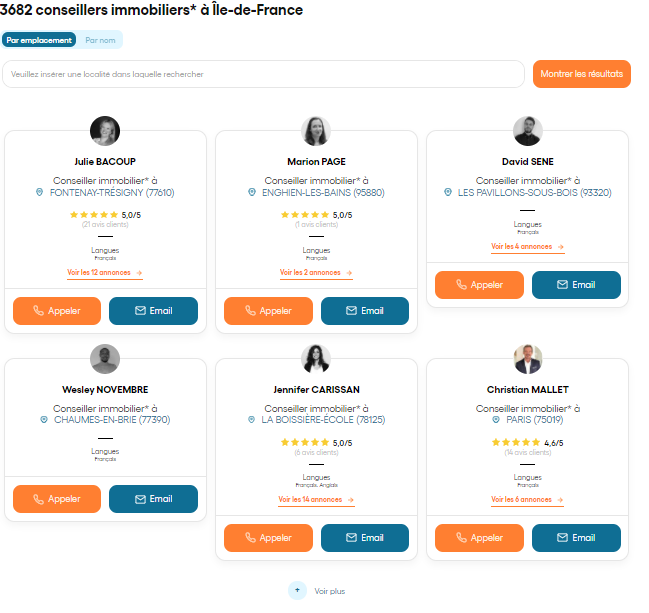
j’essaie de scraper le nom et les coordonnées des conseillers IAD avec web scraper mais je rencontre un problème avec la pagination. Le problème est qu’il n’y a pas de pages mais un chargement avec le bouton « voir plus »
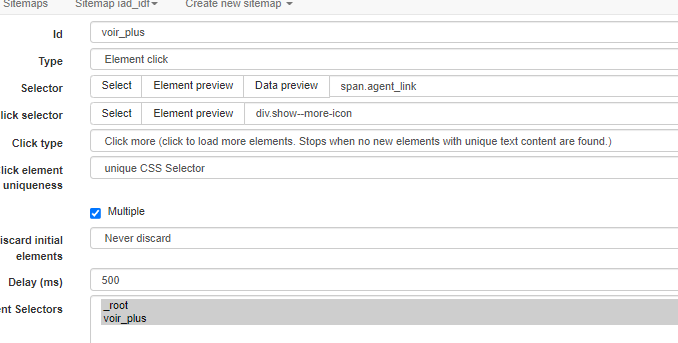
j’ai donc testé le type « Element click »
Mais je n’arrive pas à prendre d’information sur la page le sélecteur indique « Parent does not contain selected element »
J’ai déjà scrapé plusieurs site mais je ne suis jamais tombée sur une page qui n’affiche pas tout et qui doit charger les informations.
Quelqu’un a-t-il une solution pour contourner le problème ?
Merci
Ça fait un moment que je n’ai pas utilisé webscraper.io, en particlier le Element click : tu as vérifié que tu l’avais bien paramétré avec la documentation ?
Sinon, tu as directement l’URL de ~13,700 conseillers sur le sitemap, ça devrait t’éviter de passer par le moteur de recherche
Généralement dans ce cas tu peux trouver la donnée dans le code JS quand il y a un affichage « customisable » du type « voir plus » (c’est aussi le cas pour certaine pagination).
ça se fait bien en python, je ne saurais pas te dire ce que ça donne sur webscraper par contre…
L’astuce de @ClementAubry est très bonne sinon : j’imagine que le format de l’adresse mail est toujours le même pour ces personnes… Le tour est joué ^^
En fait j’ai essayé de scraper les données hier soir en Python en interrogeant l’API qui renvoie les données en JSON (enfin du HTML dans du JSON).
Au bout de 244 requêtes le programme plante (ou plutôt le serveur pour être exact) car l’URL devient trop longue (plus de 8000 caractères) car les ids de tous les conseillers déjà renvoyés par l’API sont ajoutés dans un paramètre de l’URL ignore_ids pour ne pas renvoyer les conseillers de nouveau (le site renvoie les conseillers dans un ordre aléatoire pour ne pas favoriser des conseillers qui seraient toujours en première page).
Du coup, j’ai pensé à réinitialiser l’URL au bout de 200 requêtes pour éviter d’envoyer au serveur une URL trop longue mais le site, je pense, stocke dans un cache les pages renvoyées à un client durant un certain délai donc il me renvoyait toujours les pages déjà scrapées (il fallait attendre plusieurs minutes pour avoir de nouvelles données).
L’avantage de cette méthode c’est qu’on avait 6 conseillers par requête.
Avec la solution de la sitemap c’est 1 requête = 1 conseiller. C’est plus long mais ça fonctionne bien (et plus simple à implémenter également).
Effectivement je pensais utiliser le sitemap qui réglerai ce problème.
Je suis débutante et j’ai cherché des tutos avec des outils no code. J’en ai trouvé un avec Parsehub mais impossible de le paramétrer correctement. Je vais profiter de ce week-end pour farfouiller un peu mieux dans les paramètres
En récupérant à l’aide du sitemap toutes les urls des conseillers, est-il possible de trouver une solution no code qui ouvre chaque lien et récupérer les infos que l’on souhaite avec un outil no code ? Si oui, avez-vous un tuto ou bien des conseils, je prends tout
Je suis persuadée que ça ne doit pas être très compliqué mais comme débutante difficile de trouver le bon chemin !
Merci d’avoir pris le temps de me répondre et j’espère vous lire bientôt
Sur ce site mais vu qu’il faudrait faire région par région en utilisant le sitemap c’est plus facile https://www.iadfrance.fr/sitemap/fr/agents.xml
J’ai scrapé d’autres sites moins difficiles comme capi, safti, optimhome…
Si seulement je savais comment changer une requête ! J’ai des notions de bases en programmation mais c’est vraiment basique. Je pensais me mettre à python mais je manque de temps
Bonjour, je serai intéressé pour savoir comment tu as fait, j’essaye à partir du site map avec différents outils comme Bardeen, mais je n’y arrive pas… Je voulais tout essayer avant de demander mais je suis plus capable ^^
Est-ce que tu peux me donner des pistes sur la marche à suivre ?