j’aimerais scraper les liens et les noms des utilsateurs facebook qui donnes des avis sur des pages.
Sur google sheets avec :
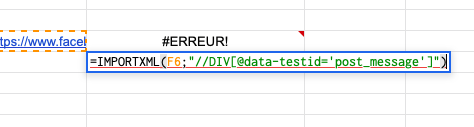
=IMPORTXML(A3;« //div[@data-testid=‹ post_message ›] ») : j’arrive à importer les commentaires.
=IMPORTXML(A3;« //span[@class=‹ fwb ›] ») : j’importe les nom, mais je n’arrive pas importer le lien qui ramene à leur compte utilisateurs.
Si quelqu’un a une idée merci à vous !
@Olivier_Niel: quand du code est écrit tel quel ici dans le corps d’un message du forum, les guillemets (single quote et double quotes) peuvent être déformés, ce qui aura pour effet de rendre la syntaxe du code invalide.
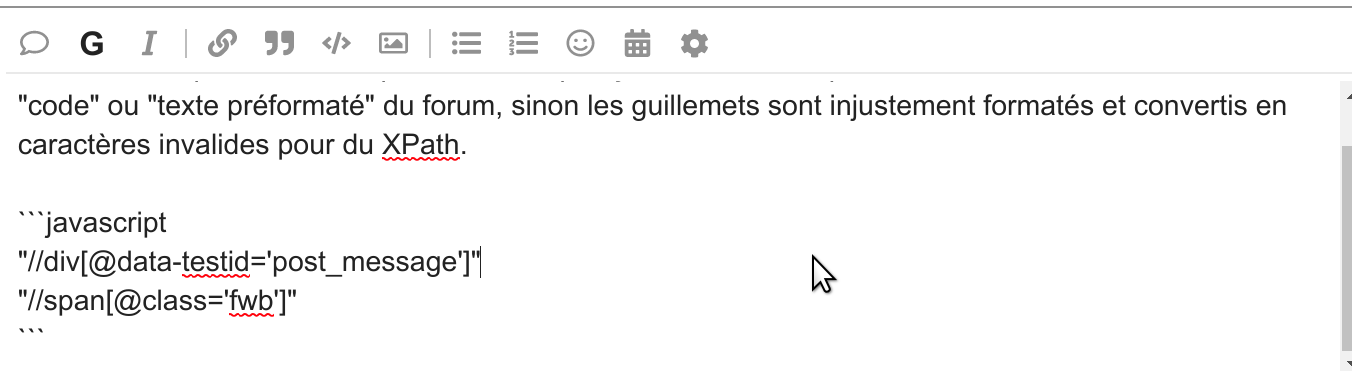
Pour les XPaths donnés par @Neo1, il faut les écrire comme ça:
Non il ne faut pas faire de copier coller tel quel ça ne fonctionne pas, il faut utiliser la fonctionnalité de « code » ou « texte préformaté » du forum, sinon les guillemets sont injustement formatés et convertis en caractères invalides pour du XPath.
Sinon, écrire le code au sein d’un bloc texte préformaté en utilisant le caractère « backtick » (simple guillemet inversé, touche alt fr + 7 sur clavier azerty windows/linux), tel que: