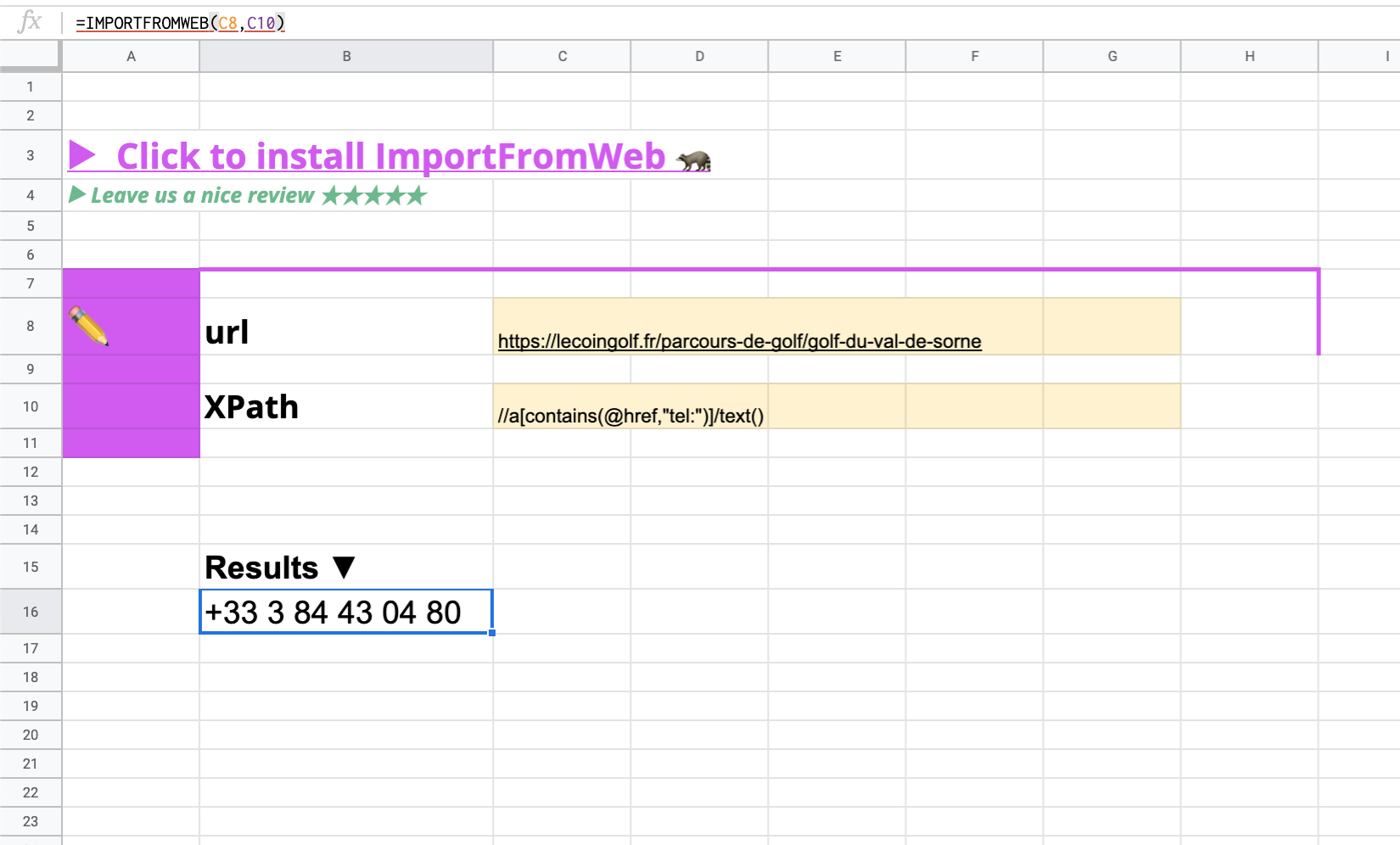
Bonjour,
J’essaye de scraper les adresses email de ce site web : Jouer au golf en France - Tous les golfs de France - Hôtel golf - Lecoingolf
Je suis débutant dans le scraping, et j’avais pour idée de le faire en 3 temps :
Mais voila, ça ne marche pas !!
Merci par avance à ceux qui vont m’aider
Bonjour, qu’est-ce qui ne marche pas, où est-ce que ça coince ?
Car dans l’idée c’est bien, il faut récupérer tous les urls du type Golf du Val de Sorne - Golf 18 trous Domaine Hôtel Resort - Lecoingolf . Et tu n’es pas obligé de passer par le nom, tu peux directement récupérer les liens c’est plus simple.
Pour ton usage, je pense que importxml est bien (je ne l’ai jamais utilisé), mais tu pourrais réaliser toutes tes étapes de scraping directement avec webscraper.io qui est très bien
2 « J'aime »
quand je faisGolf du Val de Sorne - Golf 18 trous Domaine Hôtel Resort - Lecoingolf ; //*[@id=« block_NaPXJOx »]/div[1]/div[2]/ul/li[2]/span/p/a) le résultat est #N /A
Merci ClmAubry, j’ai réussi avec Webscraper !!
2 « J'aime »
Super, content de l’apprendre !
Pour le problème avec importxml d’autres membres pourront quand même t’aider dessus, ça reste intéressant de comprendre pourquoi ça bloque.
Bonne chasse !
Mapi
Mai 11, 2020, 4:07
7
Merci @camille !@Thegeoff Je n’ai pas trouvé de bloc avec l’id block_NaPXJOx.
1 « J'aime »
Mapi
Mai 11, 2020, 4:20
13
(Voici le lien pour la lecture - sans copier la feuille:lecoingolf.fr - Google Spreadsheets )