A priori, je ne vois pas d’autre solutions que savoir coder, et savoir faire un peu de « reverse engineering ».
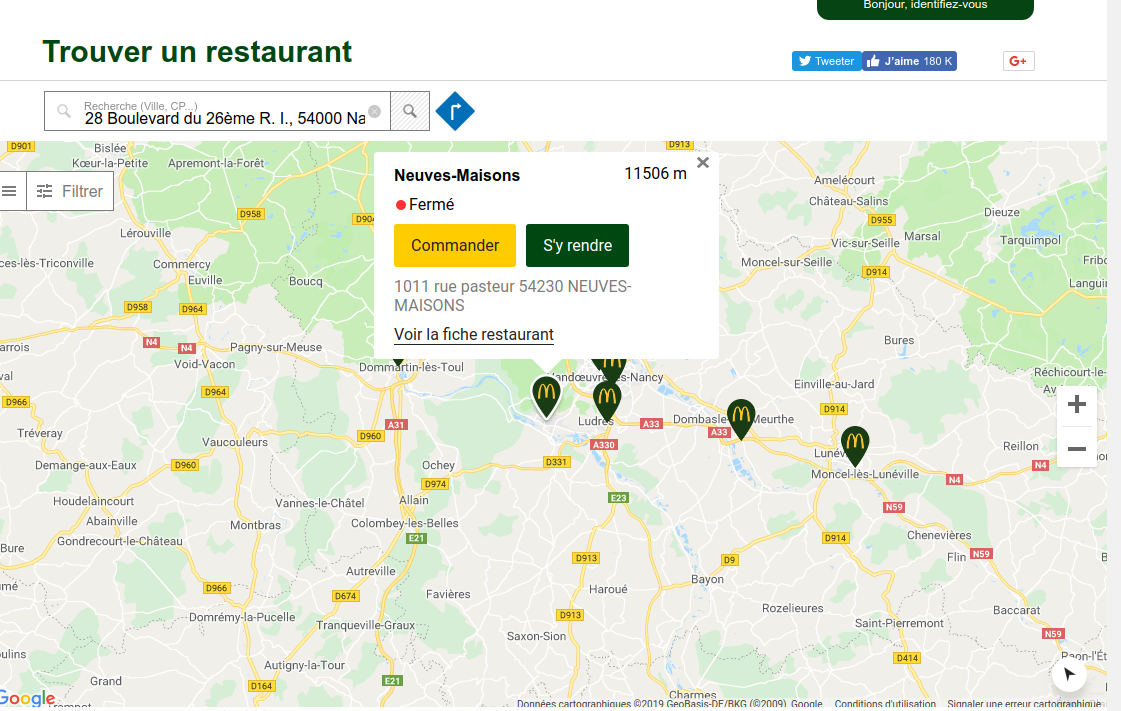
En ouvrant la console de Chrome dans le Developer Tools (Outils de Développement), en se positionnant sur l’onglet XHR, après avoir chargé la page dont tu as donné l’URL, voici ce qu’on peut observer:
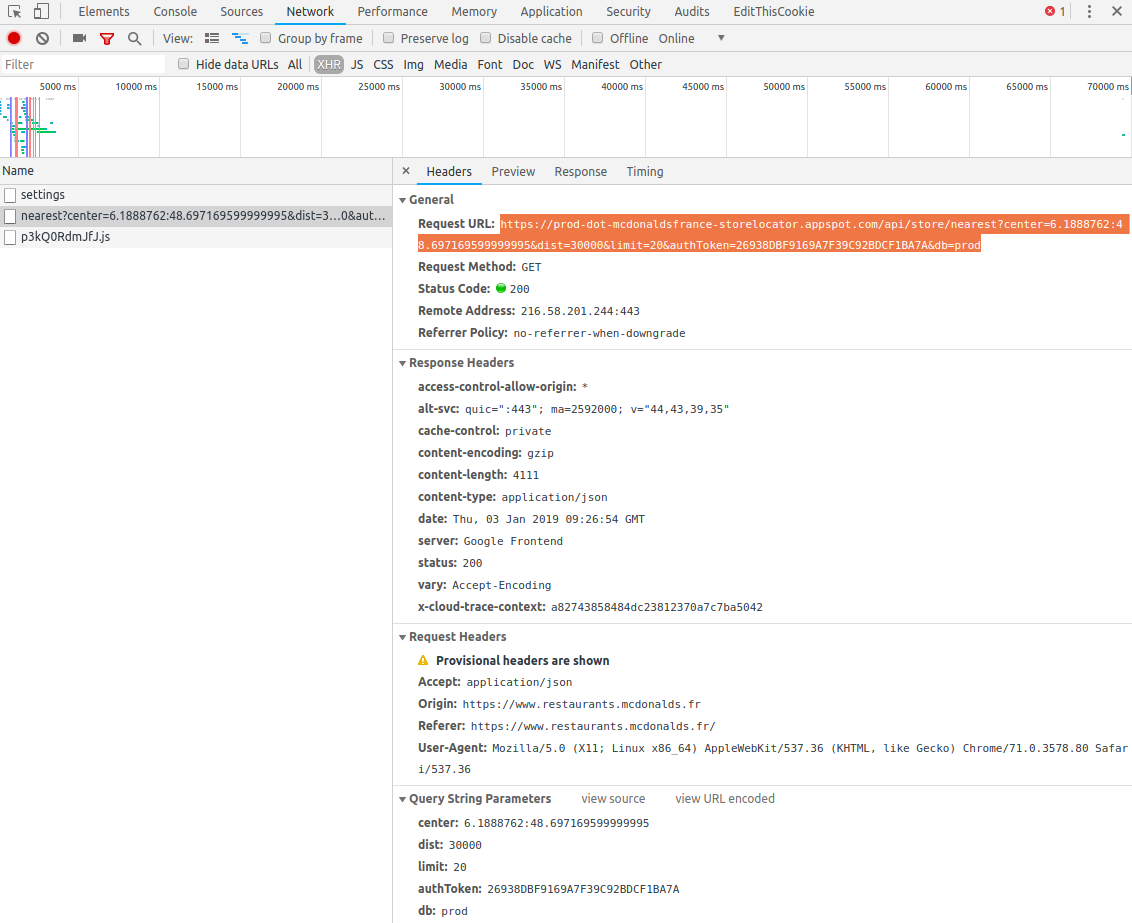
Ici, on voit qu’une requête d’API a été envoyée, dont voici l’URL:
https://prod-dot-mcdonaldsfrance-storelocator.appspot.com/api/store/nearest?center=6.1888762:48.697169599999995&dist=30000&limit=20&authToken=26938DBF9169A7F39C92BDCF1BA7A&db=prod
Les paramètres passés à l’API sont ici:
- center: 6.1888762:48.697169599999995
- dist: 30000
- limit: 20
- authToken: 26938DBF9169A7F39C92BDCF1BA7A
- db: prod
Ceux sur lesquels on peut jouer sont: center, dist, limit
En faisant varier les coordonnées géographiques du centre de le carte (paramètre center ayant pour valeur latitude:longitude, la distance depuis ce centre (paramètre center), et la limite max. de restaurants désirés dans ce cercle (paramètre limit), on peut obtenir l’intégralité des données de tous les restaurants de France.
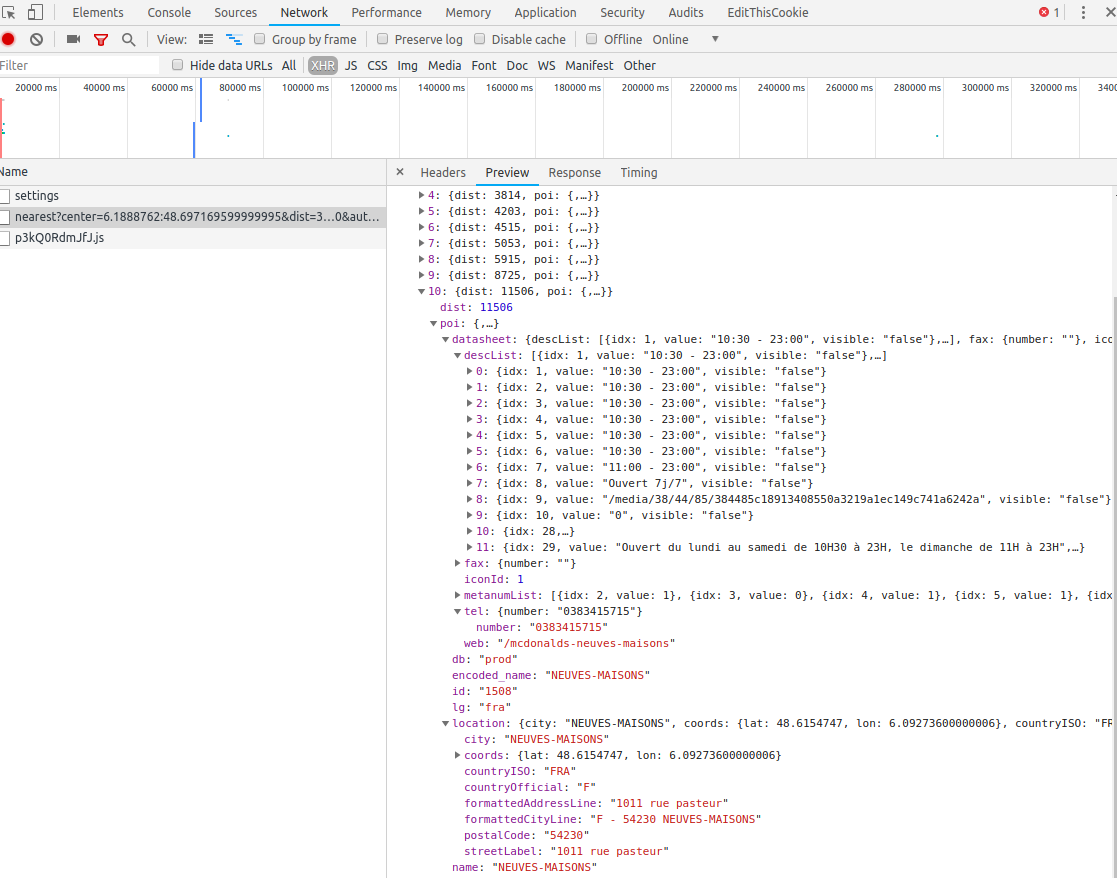
Les donnée qu’on obtient via l’API:
En version code JSON textuel :
{
"datasheet": {
"fax": {
"number": ""
},
"tel": {
"number": "0383415715"
},
"web": "/mcdonalds-neuves-maisons"
},
"db": "prod",
"encoded_name": "NEUVES-MAISONS",
"id": "1508",
"lg": "fra",
"location": {
"city": "NEUVES-MAISONS",
"coords": {
"lat": 48.6154747,
"lon": 6.09273600000006
},
"countryISO": "FRA",
"countryOfficial": "F",
"formattedAddressLine": "1011 rue pasteur",
"formattedCityLine": "F - 54230 NEUVES-MAISONS",
"postalCode": "54230",
"streetLabel": "1011 rue pasteur"
},
"name": "NEUVES-MAISONS"
}