Je vous remercie par avance pour le temps que vous m’accorderez !
Pour info, je débute seulement dans le scraping et j’utilise webscraping.io
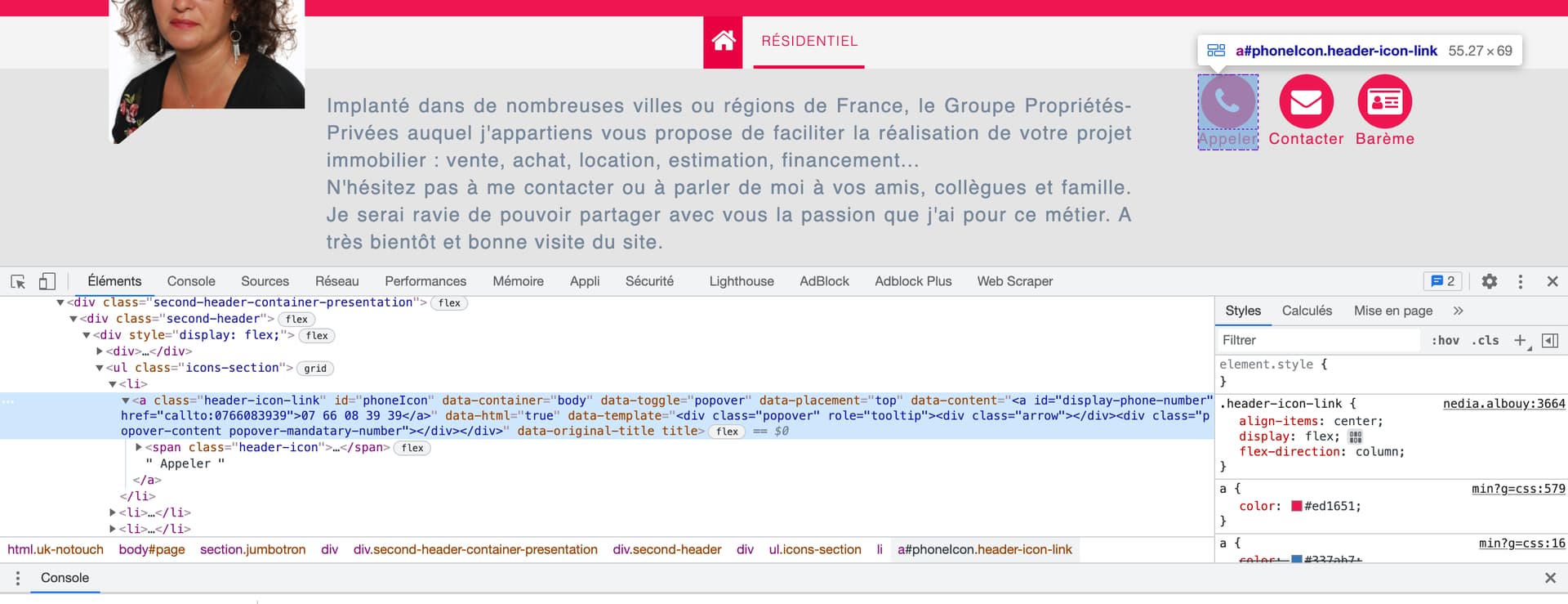
Pour mes besoins pro, j’ai besoin de scraper le nom & téléphone sur des sites de mandataires en immobilier (Iad, Safti, propriété-privée,…etc…).
Lorsque le téléphone est derrière un élément clickable, je coince pour le récupérer. J’obtiens un fichier avec « Null ».
En ayant fait quelques recherches sur ce forum et sur le site du webscrapping.io. J’ai cru comprendre qu’il était, dans ce cas, plus judicieux d’aller chercher directement le téléphone dans « Element » via un « ElementAttribute » (Webscraper et numéro de téléphone caché - #2 par Camille).
En utilisant le tutoriel (Element attribute | Web Scraper How To), je configure mon element attribute, mais il ressort toujours « null ».
J’ai trouvé le téléphone dans le « span », mais je ne peux pas utiliser le « data-content » comme un élément valide apriori…
Le site : Votre mandataire immobilier proche de chez vous
Voici à quoi cela ressemble de mon côté :
{« _id »:« proprietepriveeherault »,« startUrl »:[« Votre mandataire immobilier proche de chez vous - Page NaN em »,« type »:« SelectorText »},{« delay »:0,« id »:« element »,« multiple »:false,« parentSelectors »:[« pages »],« selector »:« #phoneIcon span »,« type »:« SelectorElement »},{« delay »:0,« extractAttribute »:« data-content »,« id »:« tel »,« multiple »:true,« parentSelectors »:[« element »],« selector »:« a »,« type »:« SelectorElementAttribute »}]}
Etant donné que je débute, je dois foirer quelque part, mais après plusieurs heures de galères, je ne trouve pas ou. Je m’en remet donc à vos connaissances !
Au plaisir,