Bonjour bonjour,
Alors je tiens à préciser que je ne suis vraiment pas un expert du scraping, j’ai regardé pas mal de tutos et je n’arrive toujours pas à résoudre ce problème …
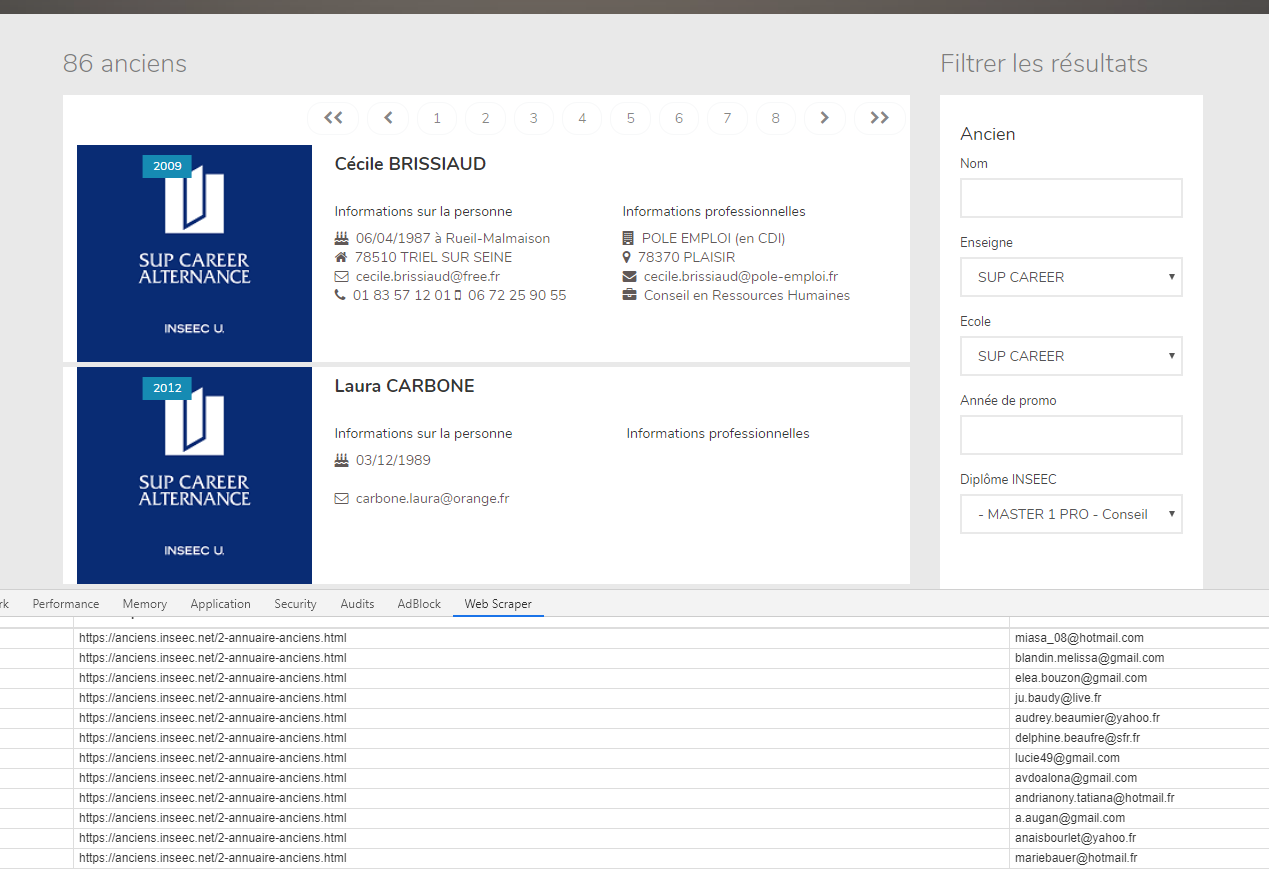
Je souhaite donc comme indiquer dans le titre scraper une base de donnée avec webscraper, qui se présente comme ceci :

Le problème c’est que la base de donnée est en HTML, et que du coup webscraper n’arrive pas vraiment à extraire les données.
L’url se termine par : annuaire-anciens.html
Sur cette base je dois demander à webscraper de sélectionner une liste déroulante, puis arrivé sur la page, de scraper du texte. Seulement il n’y arrive pas, le résultat me dit juste : rien à scraper. Peut être que c’est l’outil pour sélectionner la liste déroulante qui n’est pas le bon …

Si vous avez des pistes je suis preneur !