Bonjour à tous,
Newbee sur le GrowthHack, je suis depuis longtemps le forum GH et de près les techniques de sioux d’acquisition entre autres. Merci d’ailleurs pour les tips.
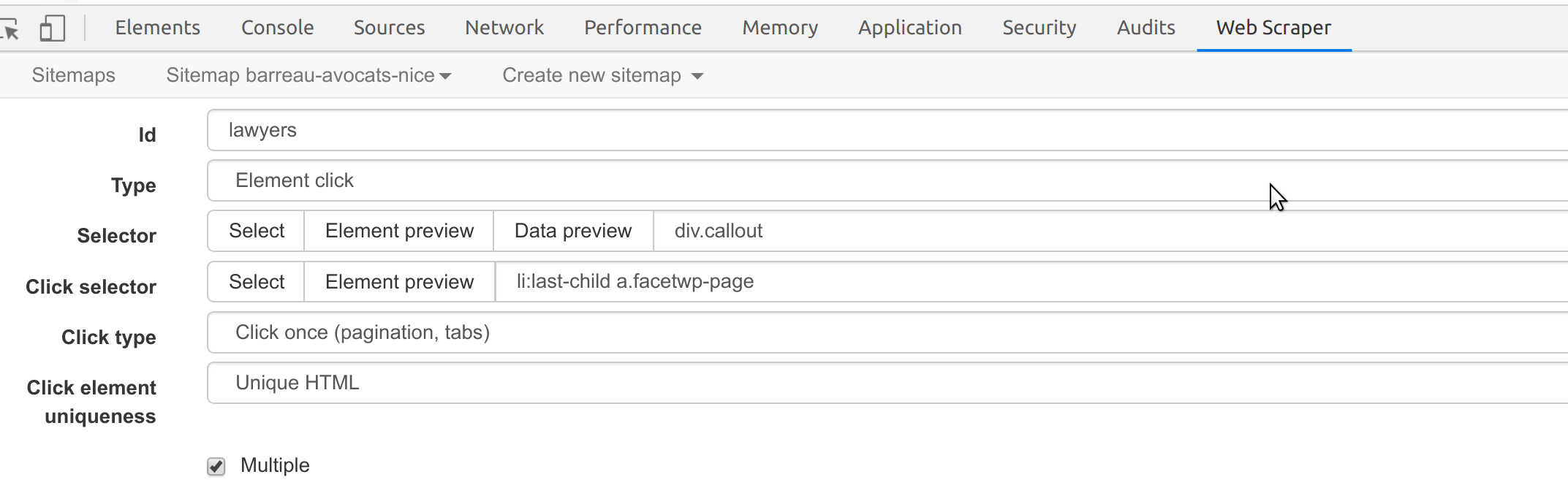
Je suis actuellement en train d’essayer de faire des exports d’adresses email de sites web et j’avoue avoir utilisé des add-ons chrome intéressants type getmail, email extractor, hunter etc.
Seulement ces derniers ne permettent que de l’extract par page (sauf erreur)
Or, je cherche à faire un export des emails présents sur chaque page d’un site (et export txt, csv, excel ou autre)
J’ai regardé dans les sujets postés depuis longtemps, mais sans succès jusqu’ici.
Pour information, il ne s’agit pas de site(s) type annuaire avec des milliers d’emails mais plutôt d’un volume de 100 à 200 emails.
Auriez-vous par hasard une idée sur la méthode à adopter ou tester ?
Merci de votre aide,
Bonne fin de weekend,
Tim