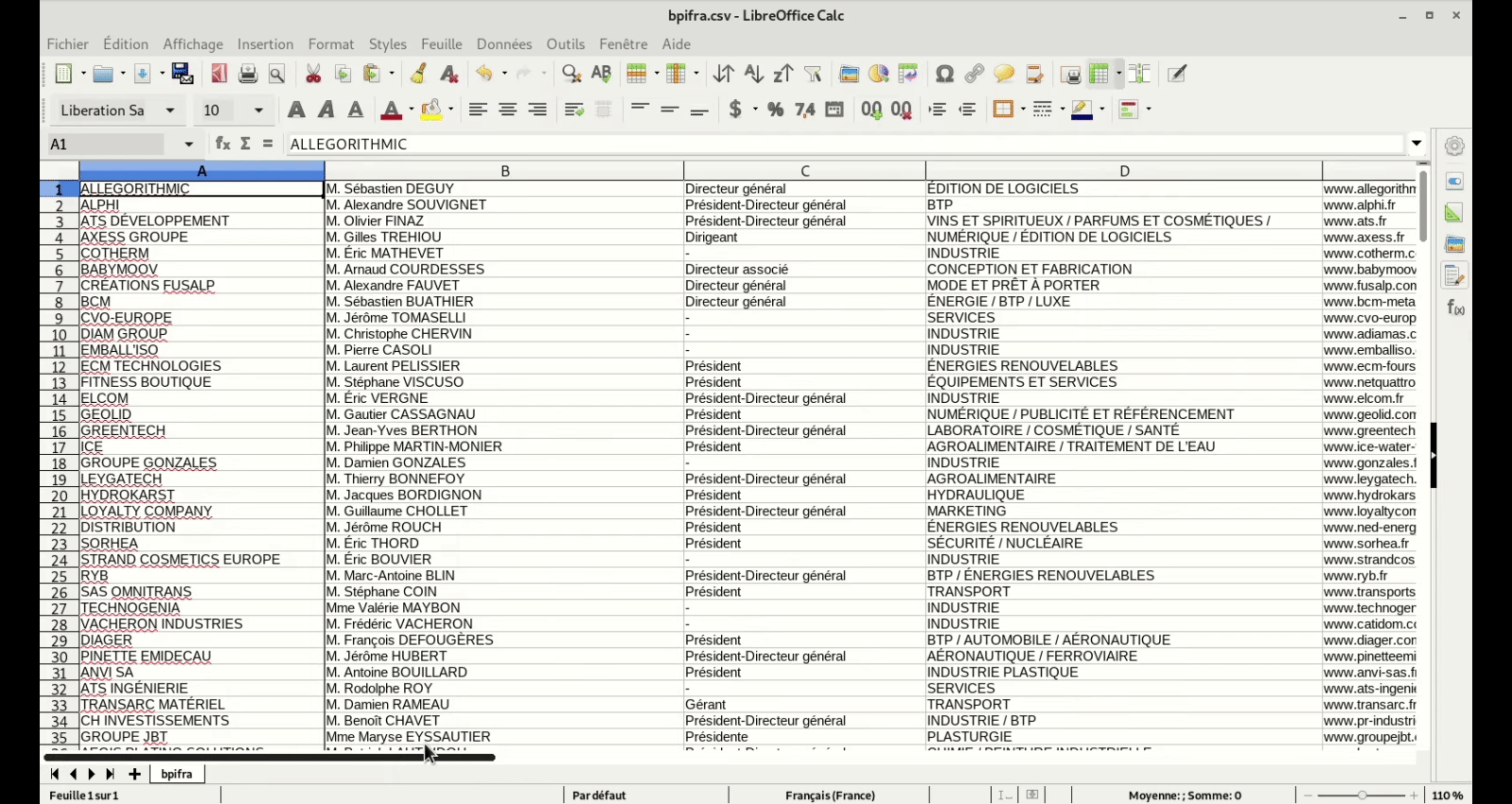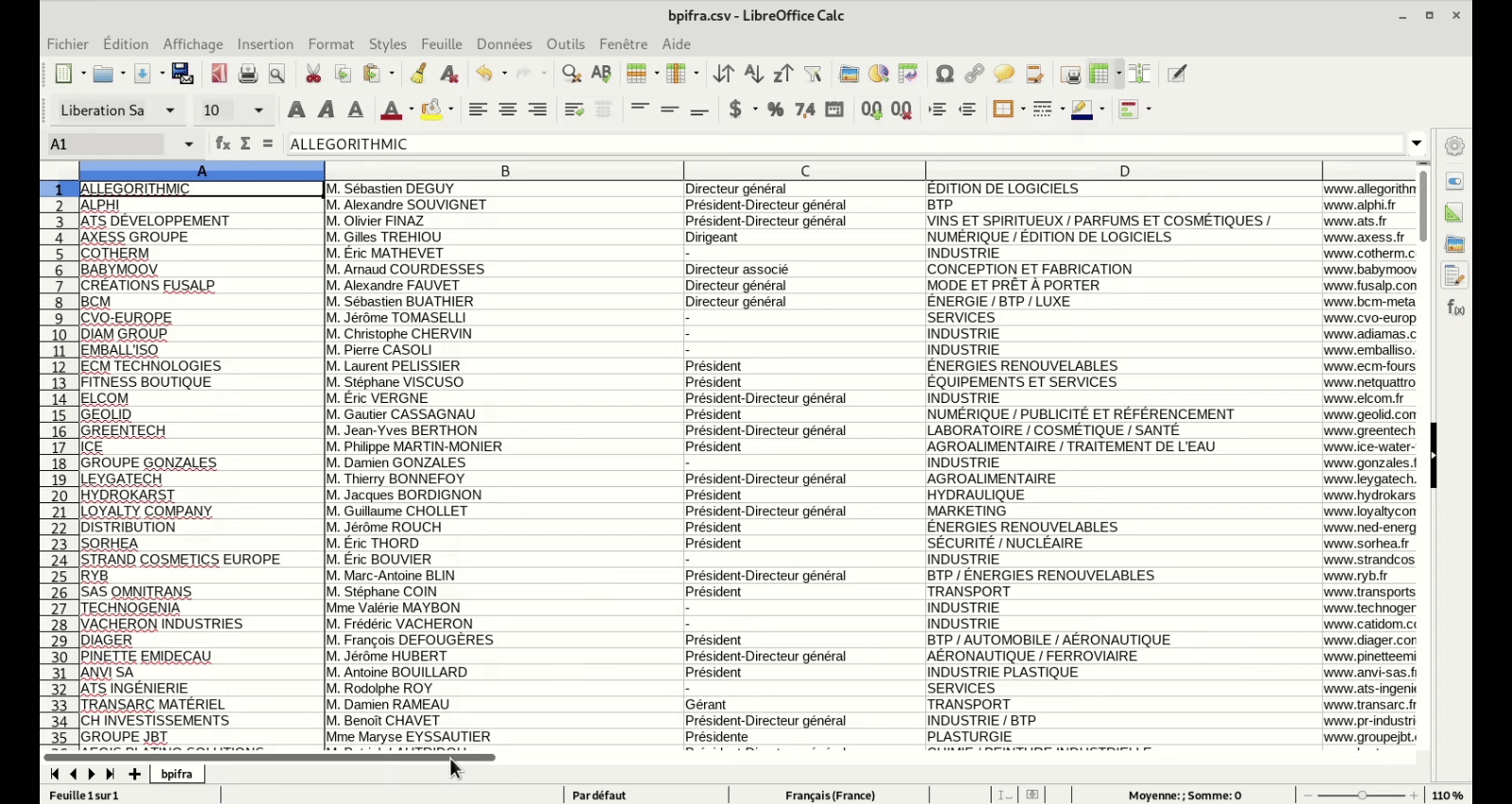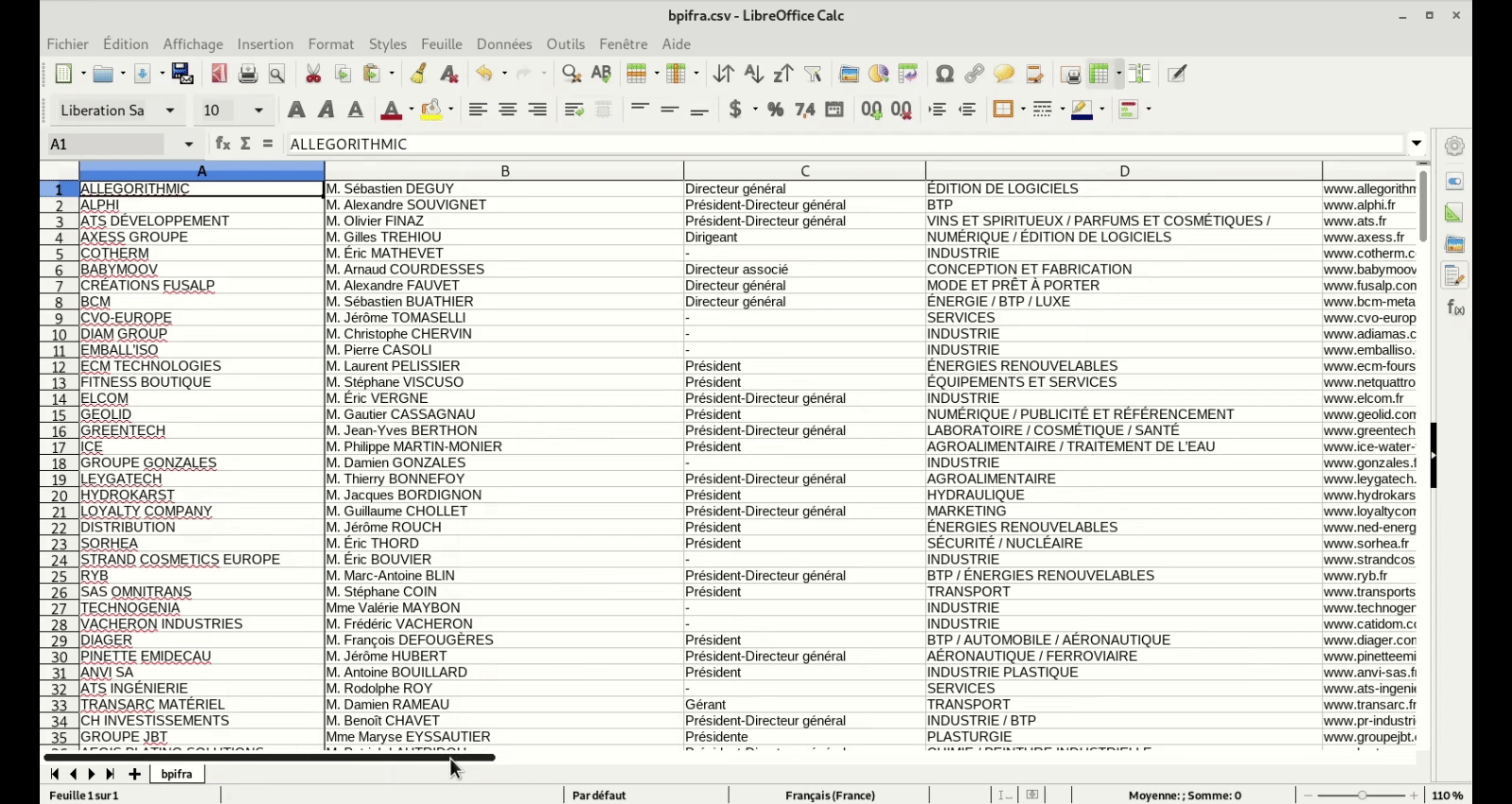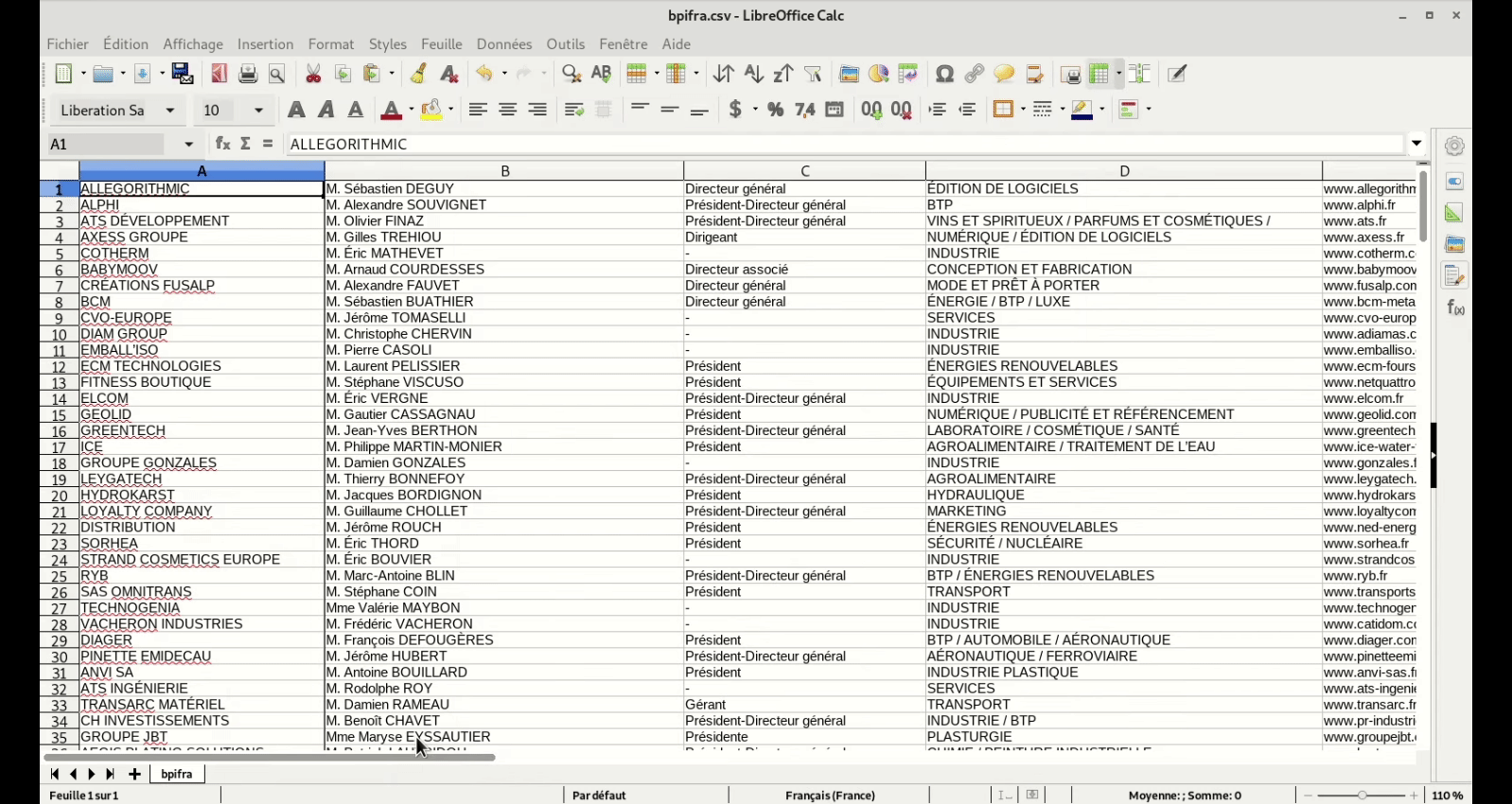
Est ce que l’un d’entre vous a déja testé le scraping de fichier pdf ?
Il y a des fichiers pdf qui ont la même structuration des infos et représente une mine d’information
Mais les données ne sont pas aussi bien structurées que dans du html (sinon, ce sera trop facile)
J’ai tenté l’export vers du html ou du xml mais le résultat n’est vraiment pas top.
Si vous avez des idées de pré-processing pour transformer un fichier pdf en fichier exploitable, n’hésitez pas ;-)))
La solution ultime est d’utiliser du NLP pour faire de la découverte d’entité automatique (savoir que tel texte est une personne, cette autre information un poste en entrerise, etc…).
Dans le cas de ton PDF, tu as 2 points positifs :
Le PDF est déjà en mode textuel (pas besoin de passer par un OCR type tesseract)
Le format des données est identique à chaque fois
Le plus simple, pour l’exemple que tu donnes, serait de faire un export textuel du PDF, et ensuite traiter l’information avec un parser custom.
De façon générale le scraping de PDF se fait en custom car les informations n’ont aucune norme type HTML ou XML. Ca passe souvent par ce type de pipelines :
a- Segmenter le PDF par page
b- Utiliser un OCR, ou exporter en mode textuel
c- Faire du traitement sémentique des données récupérées (via NLP, script custom, etc…)
d- Sauvegarder ces infos
Un autre choix, si tu as un petit budget ou peu de compétences techniques, serait de faire appel à des entreprises de BPO offshore, qui te feront un traitement manuel de tes PDF, dans le format que tu souhaites.
Merci pour tes infos.
C’est effectivement une piste j’utilise souvent le NLP avec du texte brut.
Dans ce cas, on a du texte que l’on peut repérer avec de la couleur de la taille, typo … je cherchais plutôt un moyen de profiter du fait que ce texte ait déja un format ou l’on peut repérer un texte via son format et non juste via son contenu.
Transformer ce pdf en html par exemple avec un moyen de transformer le texte avec des balises html classiques ? du style le texte est en bleu et en police XX donc je met le bon CSS ??
Quelle est la finalité exactement ? Le PDF est standardisé donc tu as une floppée de librairies possibles pour manipuler le PDF, ainsi que le convertir en un autre format. Si tu fais du NLP tu dois être plus à l’aise sur Python. Une simple recherche « python pdf to html » te donneras déjà pleins de choses à tester.
D’expérience l’utilisation de ces librairies n’est pas fiables sur des sets de données hétérogènes car il faut que le PDF soit bien généré pour bien faire la conversion, et si tu as des milliers de documents tu passes plus de temps à faire de la vérification que le traitement en lui même. Au final c’est plus rapide de le faire à la main.
Si tout tes fichiers sont identiques à l’exemple que tu donnes, c’est assez rapide de faire un générateur de HTML avec les bonnes couleurs, font, etc… avec uniquement l’utilisation de l’export en texte (ces valeurs seront fixées par toi bien sûr).
Pour aller plus vite, je crée des aliases et fonction avec Sed ou Grep ( pour de petit fichier et autre command pour de gros volume) selon les besoins (ex: sed « /./!d;s/[1]//;s/[ \t]$// ») pour enlever les tabulation et ligne vide, un autre pour ajouter les , ou ; (csv) à la fin ou debut de chaque ligne etc.
En 5 min, bravo!
Voila de quoi prouver que, pour des besoins ponctuels, et dans la majorité des cas, c’est plus profitable d’engager un expert que d’apprendre à le faire.
Edit : je ne vise personne du thread, c’est plus une remarque général. J’ai des clients qui préférent perdre des heures/jours à apprendre à scraper pour économiser et éviter de payer un expert qui peut le faire en 5min
J’utilise un outil de PDFLib : TET, il te sort un fichier au format xml avec selon les paramètres les coordonnées de la ligne, des caractères, des mots. C’est un outil très pratique.
On peut le tester gratuitement sur quelques pages.