Bonjour à toute la communauté !
Je vous contacte aujourd’hui car je suis bloqué sur un programme en Python qui a pour but d’envoyer en masse un message à tous les membres d’un plateforme.
Je précise que je viens de démarrer il y a 3 jours sur Python et que je reste novice sur tout ce que m’offre Python et ses différents librairies de scraping 
A ce jour l’algorithme est finalisé ainsi que le code, par contre je me heurte à un souci que je n’arrive pas à résoudre : la connexion sur le site pour envoyer des messages.
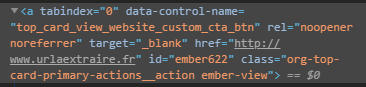
Ci-dessous voici un extrait des champs que je dois remplir pour m’identifier (j’ai un compte sur cette plateforme ) :

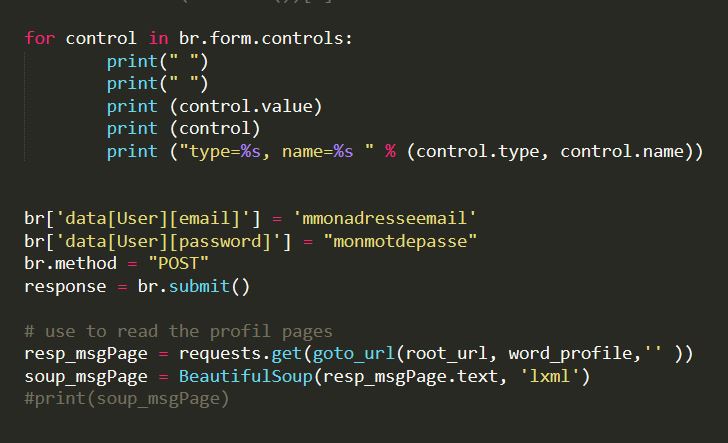
Voici une partie du code qui me permet de soumettre mes informations de connexion :
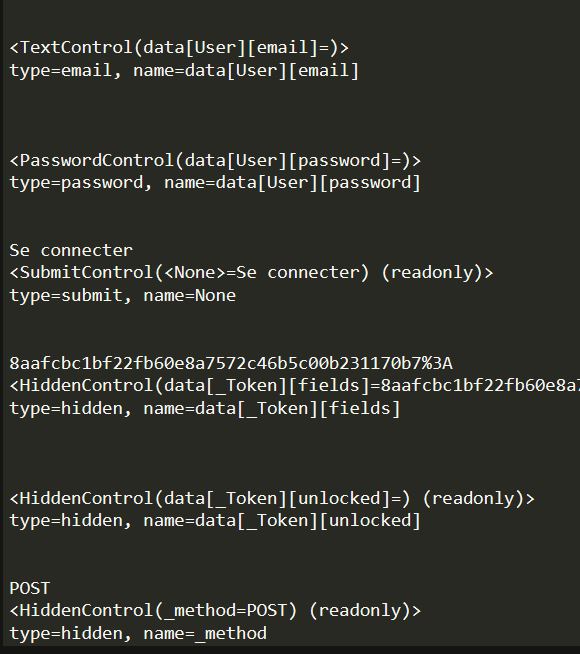
Mon problème est le suivant : les noms des champs que je spécifie ne sont apparemment pas reconnus et je ne comprends pas pourquoi. J’ai utilisé pas mal de print pour débugguer mon souci et je n’ai pas la réponse.
Voici un extrait du log :
Ainsi que de l’erreur :
Si quelqu’un à une idée pour m’aider à comprendre pourquoi les noms des login & mot de passe que je lui fournis ne sont pas reconnus je suis preneur
Peut être il y a une manière plus simple d’émuler mon propre navigateur où je suis connecté ? Ou alors je me trompe totalement sur l’approche ?
Merci d’avance pour votre aide précieuse ! 
 Je commence à être plutôt très autonome et je finirai presque par adorer Python !
Je commence à être plutôt très autonome et je finirai presque par adorer Python !