Bonjour à tous !
Je commence tout juste dans le monde du Growthhacking, et je découvre les joies du scraping.
Je cherche à scrapper des adresses mail + nom d’établissement de CHR / restauration sur des zones géographique définis via TripAdvisor.
J’ai mis en place l’outil webscraper sur un pc indépendant qui tourne que pour ça, cependant dans mon selector graph il doit y avoir un problème, car je ne parviens pas à aller sur la page suivant pour effectuer mon acquisition.
Tout se passe super bien sur la première page, donc les 30 premiers restaurant, et par la suite web scraper s’éteint et arrête.
J’en déduis ainsi qu’il n’arrive pas à passer la page suivant malgré que j’ai essayé différentes configurations…
Si certains arrivent à éclairer ma lanterne à ce niveau, ca serait absolument super !!
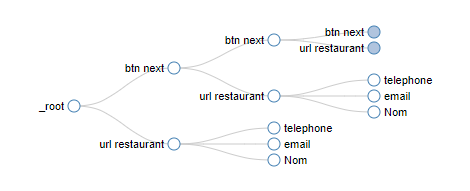
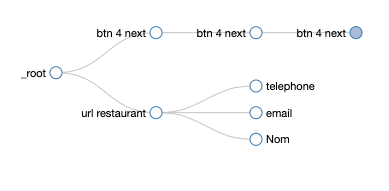
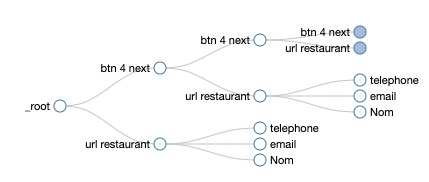
Voici mon sitemap sur la ville de Bergerac par exemple :
{"_id":« bergerac »,« startUrl »:[« https://www.tripadvisor.fr/Restaurants-g17759543-Bergerac_Dordogne_Nouvelle_Aquitaine.html"],« selectors »:[{« id »:« restaurantunaun »,« parentSelectors »:["_root",« pagesuivante »],« type »:« SelectorLink »,« selector »:"div.dzomp:nth-of-type(1) a »,« multiple »:true,« delay »:0},{« id »:« mail »,« parentSelectors »:[« restaurantunaun »],« type »:« SelectorLink »,« selector »:« div.bKBJS:nth-of-type(2) a »,« multiple »:false,« delay »:0},{« id »:« pagesuivante »,« parentSelectors »:["_root"],« type »:« SelectorLink »,« selector »:« a.nav »,« multiple »:true,« delay »:0}]}
Et voici le graph qui en découle
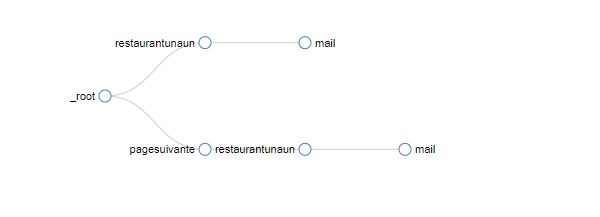
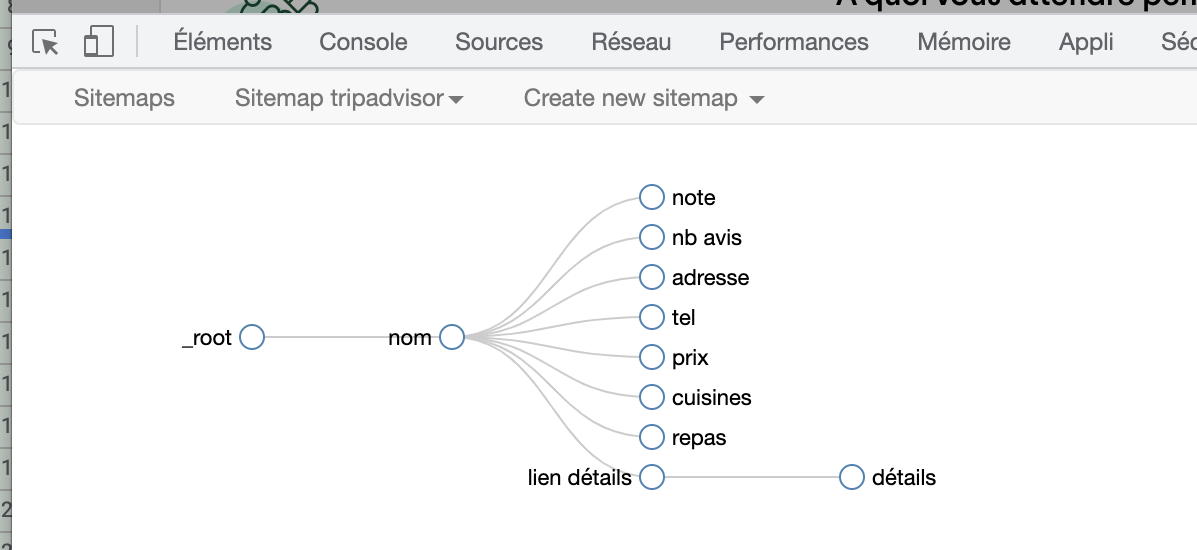
Pour l’exemple il n’y a que le mail qui sort, mais je prends aussi le nom avec
Ps : si quelqu’un sait comment extraire le numéro de téléphone avec, ça serait absolument splendide !!
Merci beaucoup !!