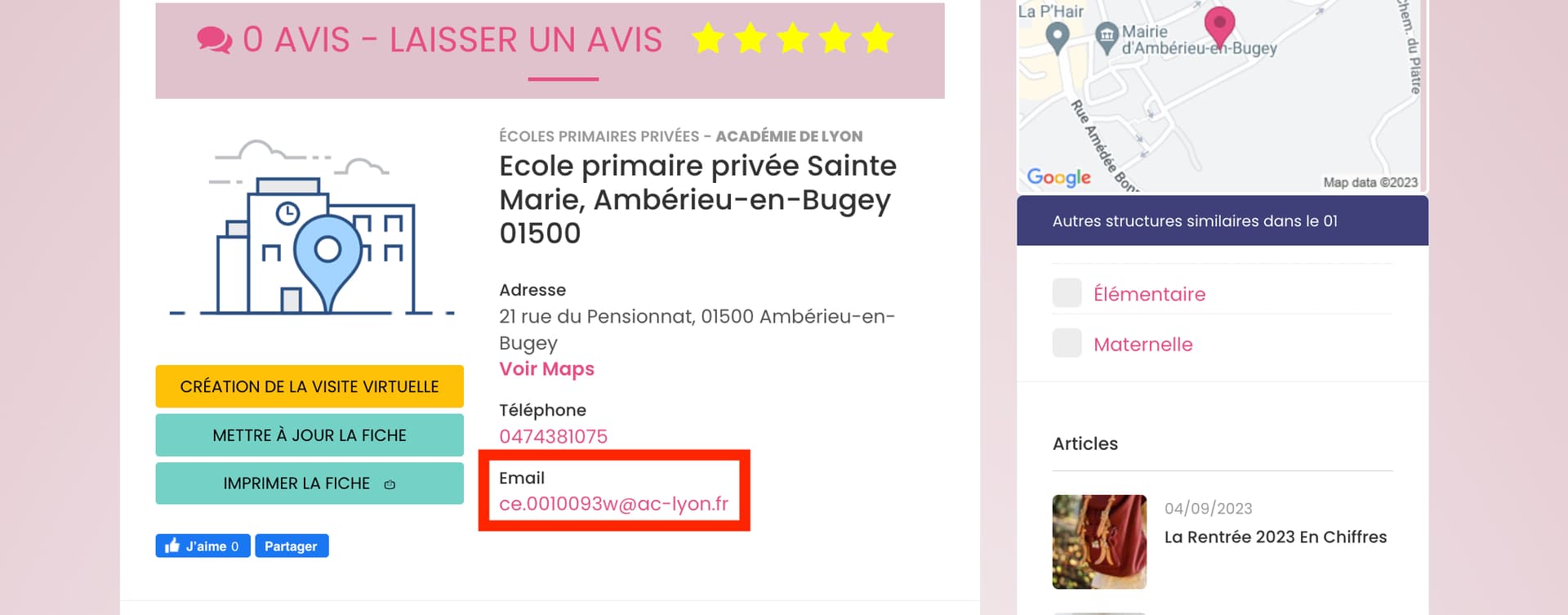
Bonjour tout le monde,
J’ai besoin de scraper cet annuaire (Écoles primaires privées). J’ai besoin d’obtenir le prénom, le nom, le téléphone et le mail des différentes écoles.
Pouvez vous me donner une astuce pour faire ca svp
Merci !
Bonjour tout le monde,
J’ai besoin de scraper cet annuaire (Écoles primaires privées). J’ai besoin d’obtenir le prénom, le nom, le téléphone et le mail des différentes écoles.
Pouvez vous me donner une astuce pour faire ca svp
Merci !
Yes, c’est entièrement possible!
Il faut:
curl 'https://www.1001ecolesprivees.fr/annuaire/1-ecoles' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \
-H 'Accept-Language: fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7' \
-H 'Cache-Control: max-age=0' \
-H 'Connection: keep-alive' \
-H 'Cookie: _ga=GA1.2.1106143144.1696264940; _gid=GA1.2.146124265.1696264940; cb-enabled=accepted; _ga_X4R2SMSCTW=GS1.2.1696264940.1.1.1696264994.6.0.0' \
-H 'Referer: https://www.growthhacking.fr/' \
-H 'Sec-Fetch-Dest: document' \
-H 'Sec-Fetch-Mode: navigate' \
-H 'Sec-Fetch-Site: cross-site' \
-H 'Sec-Fetch-User: ?1' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36' \
-H 'sec-ch-ua: "Google Chrome";v="117", "Not;A=Brand";v="8", "Chromium";v="117"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
--compressed
curl 'https://www.1001ecolesprivees.fr/annuaire/1-ecoles/dep:01' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \
-H 'Accept-Language: fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7' \
-H 'Cache-Control: max-age=0' \
-H 'Connection: keep-alive' \
-H 'Cookie: _ga=GA1.2.1106143144.1696264940; _gid=GA1.2.146124265.1696264940; cb-enabled=accepted; _gat=1; _ga_X4R2SMSCTW=GS1.2.1696264940.1.1.1696265069.32.0.0' \
-H 'Referer: https://www.1001ecolesprivees.fr/annuaire/1-ecoles' \
-H 'Sec-Fetch-Dest: document' \
-H 'Sec-Fetch-Mode: navigate' \
-H 'Sec-Fetch-Site: same-origin' \
-H 'Sec-Fetch-User: ?1' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36' \
-H 'sec-ch-ua: "Google Chrome";v="117", "Not;A=Brand";v="8", "Chromium";v="117"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
--compressed
curl 'https://www.1001ecolesprivees.fr/etablissement/1341-ecole-primaire-privee-sainte-marie' \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \
-H 'Accept-Language: fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7' \
-H 'Connection: keep-alive' \
-H 'Cookie: _ga=GA1.2.1106143144.1696264940; _gid=GA1.2.146124265.1696264940; cb-enabled=accepted; _ga_X4R2SMSCTW=GS1.2.1696264940.1.1.1696265081.20.0.0' \
-H 'Referer: https://www.1001ecolesprivees.fr/annuaire/1-ecoles/dep:01' \
-H 'Sec-Fetch-Dest: document' \
-H 'Sec-Fetch-Mode: navigate' \
-H 'Sec-Fetch-Site: same-origin' \
-H 'Sec-Fetch-User: ?1' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36' \
-H 'sec-ch-ua: "Google Chrome";v="117", "Not;A=Brand";v="8", "Chromium";v="117"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
--compressed
Est-ce que tu sais coder — en Python peut-être?
Sinon, tu peux me DM, ou me contacter juste là
![]()
je ne connais pas bien les outils no-code mais en scraping classique on peut facilement construire toutes les urls de résultats, ils sont construits par https://www.1001ecolesprivees.fr/annuaire/X-ecoles/dep:YY X varie de 1 à 3 et YY prends les valeurs des départements, ensuite faut gérer la pagination, puis récupérer les données qui sont dans le html donc pas de difficultés mais faut savoir coder (par exemple python / scrapy en ce qui me concerne)
J’ai répondu en même temps que @SashaLobstr …ou presque … bon on se complète, à toi de voir si tu veux coder, sous-traiter (auquel cas tu peux aussi me contacter) ou trouver un outils no-code
A vérifier, mais il me semble que ce site ne fait que reprendre les données publiées par le ministère ICI.
Du coup tu as déjà tout (publiques et privées) en csv, avec les emails.
A toi de jouer ![]()
édit : pour des données à jour, la source originale