Fugazi
Novembre 8, 2024, 3:48
1
Bonjour tout le monde, j’espère que vous allez bien !
J’essaye de scraper le lien suivant : https://www.verif.com/top/revenue-r0/france-rcoun/auvergne-rhone-alpes-rreg/ mais quand j’utilise soit des applis no-code soit des scripts Python, le site m’affiche un simple « Not Found ». Je n’arrive pas à craquer le problème.
Quelqu’un a déjà rencontré cette barrière et a trouvé une solution ?
Merci à vous !
Je viens d’essayer avec un script en JS et pareil.
Tu as besoin de quoi ici?
Fugazi
Novembre 8, 2024, 4:25
3
Ouais, tu as vu ? Étonnant, j’ai jamais eu cette problématique, sauf avec UberEats et encore c’était pas aussi « précis ».
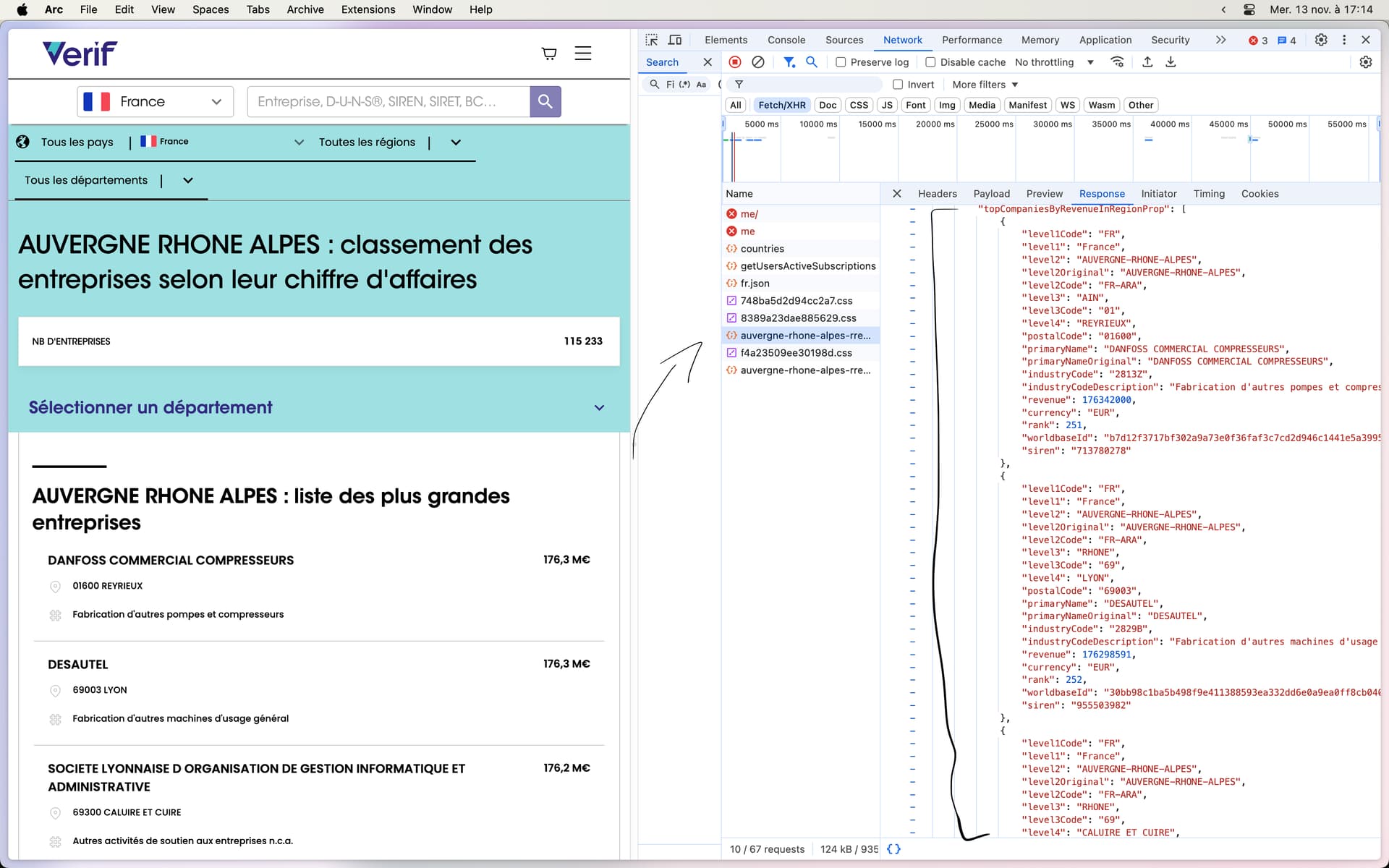
Je veux la liste des entreprises et tout ce qui est relié à elle.
Je viens de capter qu’on a les data dans un .JSON mais ça me fait faire les 6 pages à la main :
Prendre le .JSON (sa réponse)
Convertir le JSON to CSV
Télécharger le CSV dans un tableur
Prendre les data que je souhaite
Mais ça fait bcp d’étape pour un truc aussi simple…
1 « J'aime »
J’ai changé de compte je vais être actif avec celui là maintenant. (Bloodyoo était un compte pour lurker)
Essaye avec un navigateur headless ou peut être ici https://web.archive.org/web/20240620130937/https://www.verif.com/top/revenue-r0/france-rcoun/auvergne-rhone-alpes-rreg/
1 « J'aime »
Fugazi
Novembre 8, 2024, 4:32
5
J’ai déjà essayé avec le nav en headless et tout les trucs traditionnels, malheureusement c’était pas un succès.
Merci pour le tips du wayback mais c’est super lent à chaque fois ce site :')
Encore merci pour ton aide, c’est très sympa Gaetan !
Ouais, je voulais te proposer le cache google mais on dirait qu’il n’y a rien
Nice!, tu passes la protection?
Fugazi
Novembre 14, 2024, 9:22
10
Je dirais plus contourner que passer car en soit ça me demande d’extraire page par page la réponse, de convertir le json en csv et de faire mon tri. Pas opti mais ça fonctionne !