J’ai écrit un tuto sur medium qui explique comment scrapper un site e-commerce pour récupérer un catalogue, sans connaissance technique. J’utilise l’outil Webscrapper . J’ai pensé que ça pourrait intéresser pas mal de monde ici !!
Hello,
merci pour le partage TOP, j’ai testé Dexi.io dans le même type, ça fonctionnait bien & on une offre 7 jours gratuit
Webscrapper à l’air top, à tester c’est freemium ?
Yes c’est freemium. Ils ont des features payantes pour faire du scrapping automatique et scheduled.
Je ne connaissais pas Dexi.io je vais regarder thanks
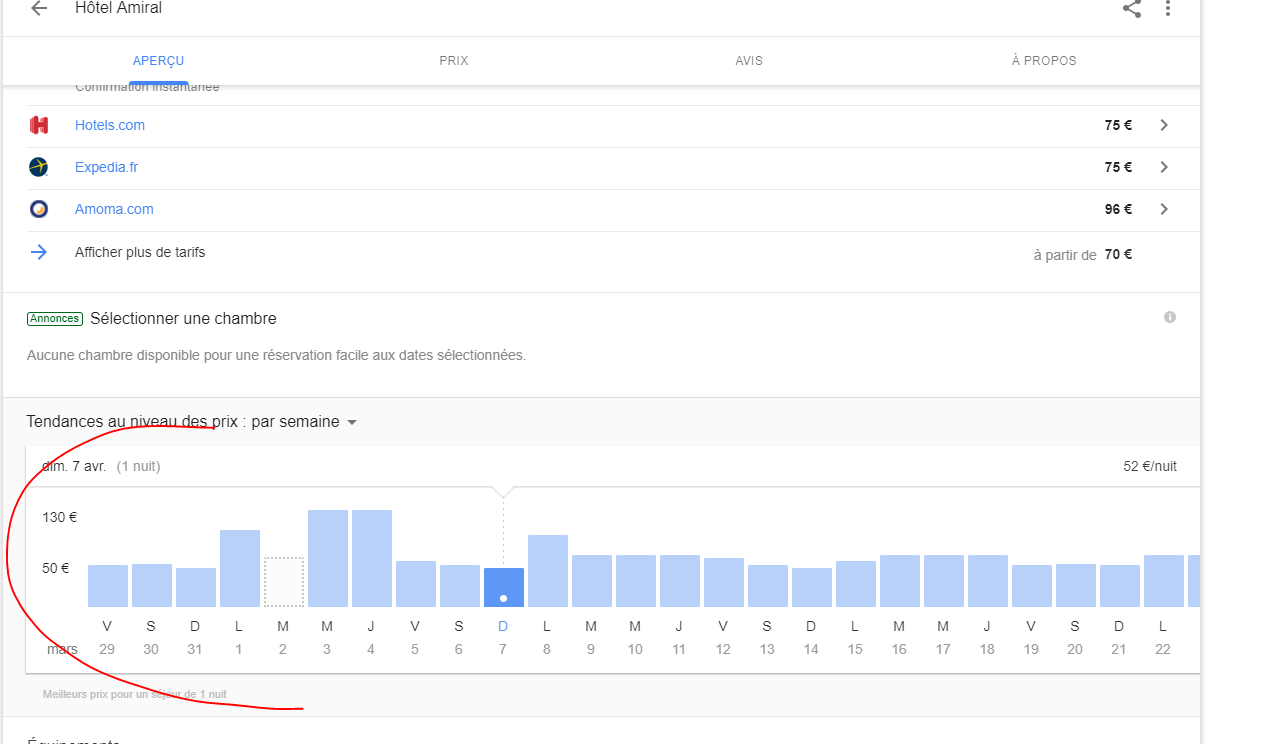
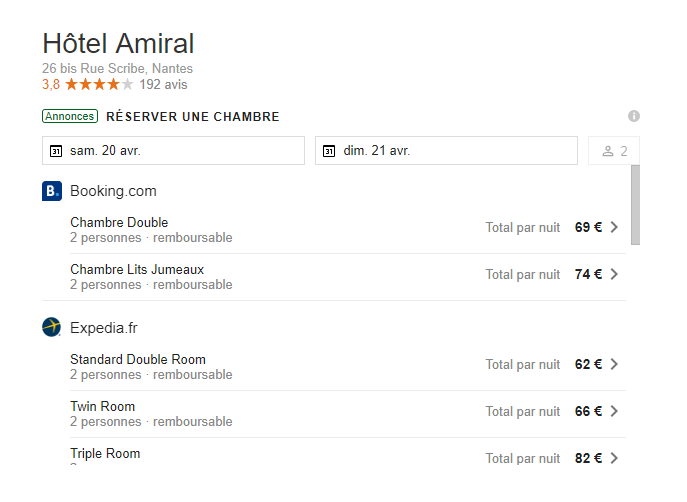
J’ai tenté moi aussi de récupérer les données de prix sur ton url. Malheureusement, je n’y suis pas arrivé . On dirait que le roi des scrappeurs est difficile à scrapper ^^.
Essaye sur un autre comparateur de prix d’hôtels, tu auras peut-être plus de chance ! A dispo pour t’aider :).
Je n’ai pas assez d’infos pour vous aider.
Les gars, pouvez vous me dire plus précisément à quelle étape vous bloquez, et donner l’export JSON de votre sitemap Webscraper?
Je ne sais pas si cela correspond à ce que veut faire @christohpe car il avait l’air de chercher plutôt les évolutions de prix dans le temps.
Mon scrap se base sur un un selectorpopuplink puis sur du scrap de type text. Malheureusement, je n’arrive pas à en tirer grand chose.
Webscraper lorsque tu le lances, ne reprend pas les paramètres par défaut de ton navigateur, en gros pas d’extensions activées, et du coup encore moins de User Agent spoofé. Pas moyen de se faire passer pour une app mobile avec je pense… Est ce le cas?
En tout cas pour ma part, je gérerais ce type de cas via du headless browser.
Oui, je te confirme que Webscrapper ne reprend pas les paramètres du navigateur. Je ne connaissais pas le headless browser. Est-ce que tu as des ressources à me conseiller sur ce sujet @scrapping_expert ?
J’avais rencontré des problèmes en essayant de scrapper des annonces sur Seloger. Mon scrap fonctionnait bien. En revanche, je n’arrivais pas à récupérer tous les résultats (une limite devait sans doute être atteinte).
Merci pour le tuto, par contre on est d’accord que cela ne fonctionne que pour les données affichées par le navigateur ? je ne peux pas aller chercher des balises html non affichées ?
Ah oui webscraper propose le type « html », mais je n’arrive pas à comprendre comment lui indiquer l’élément html que je souhaite, et impossible de trouver d’autres tutos en français sur cet outil…
J’ai un input qui est « hidden » à récupérer, si quelqu’un a un bon lien pour comprendre comment faire ?
Je crois que je me suis trompé en postant le tuto Chrome Headless en date du 03 Avril dans ce sujet, j’aurais dû le mettre ailleurs… Sorry car ça prête à confusion !
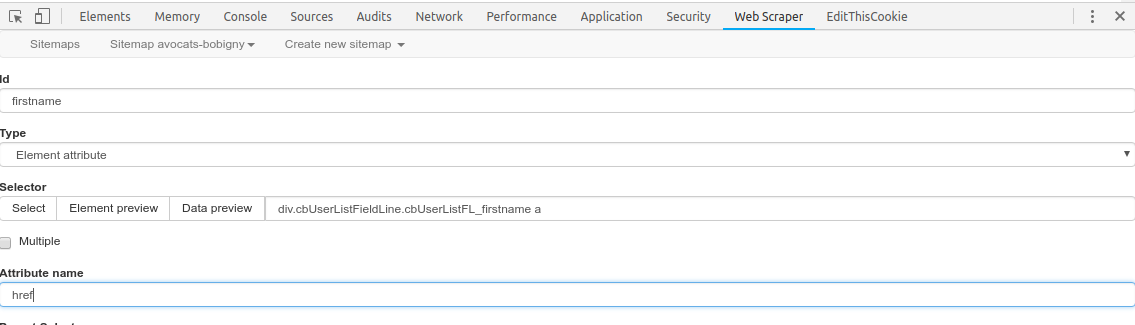
Sinon @EwenK pour en revenir à ta question, pour indiquer à l’outil quel élément HTML tu veux cibler, il faut utiliser les sélecteurs (CSS ou XPath).
Dans le cas de Webscraper, il s’agit des sélecteurs CSS. Et pour ce qui est de cibler un input de type « hidden », le sélecteur CSS correspondant est: input[type=hidden]
Si tu veux récupérer des données qui sont présentes dans des attributs des balises HTML (en l’occurrence des données « non affichées par le navigateur »), il faut spécifier à Webscraper le type de l’élément que tu cibles, c’est à dire « Element attribute », puis lui indiquer le nom de l’attribut ciblé:
En effet mon premier post concernait le Tuto initial de Webscraper et non pas celui de Chrome Headless, mais j’irai le voir dans un second temps ceci dit.
Merci pour les explications, je vais creuser cela !
Je suis en train de creuser le type « Element click », qui permet pour ceux que ça intéresse de cliquer sur un bouton pour récuperer des données qui par exemple nécessitent un appel Ajax, comme c’est souvent le cas pour les numéros de téléphone ou parfois pour afficher plus d’éléments (annonces, articles…)
Je fais donc cela :
type : « Element Click »
Click selector : je selectionne le bouton à cliquer
Click type : « Click once » (pour récupérer juste un numéro)
Click element uniqueness : Unique Text
Delay : « 2000 ms » (pour temporiser le click)
Par contre j’ai une question, en plus du « Click Selector » il existe un « element Selector ». Je pensais intuitivement qu’il s’agissait de l’élément à récupérer une fois cliqué sur le bouton, j’ai donc sélectionné l’endroit où apparait mon téléphone, mais ça ne fonctionne pas. Quelqu’un a une idée ?
Sachant que j’ai de toute façon réussi à récupérer le télephone en ajoutant un autre selector après de type « Text » qui récupére le numéro de téléphone une fois cliqué dessus, mais ça m’intrigue de ne pas bien saisir le fonctionnement du Click Selector.
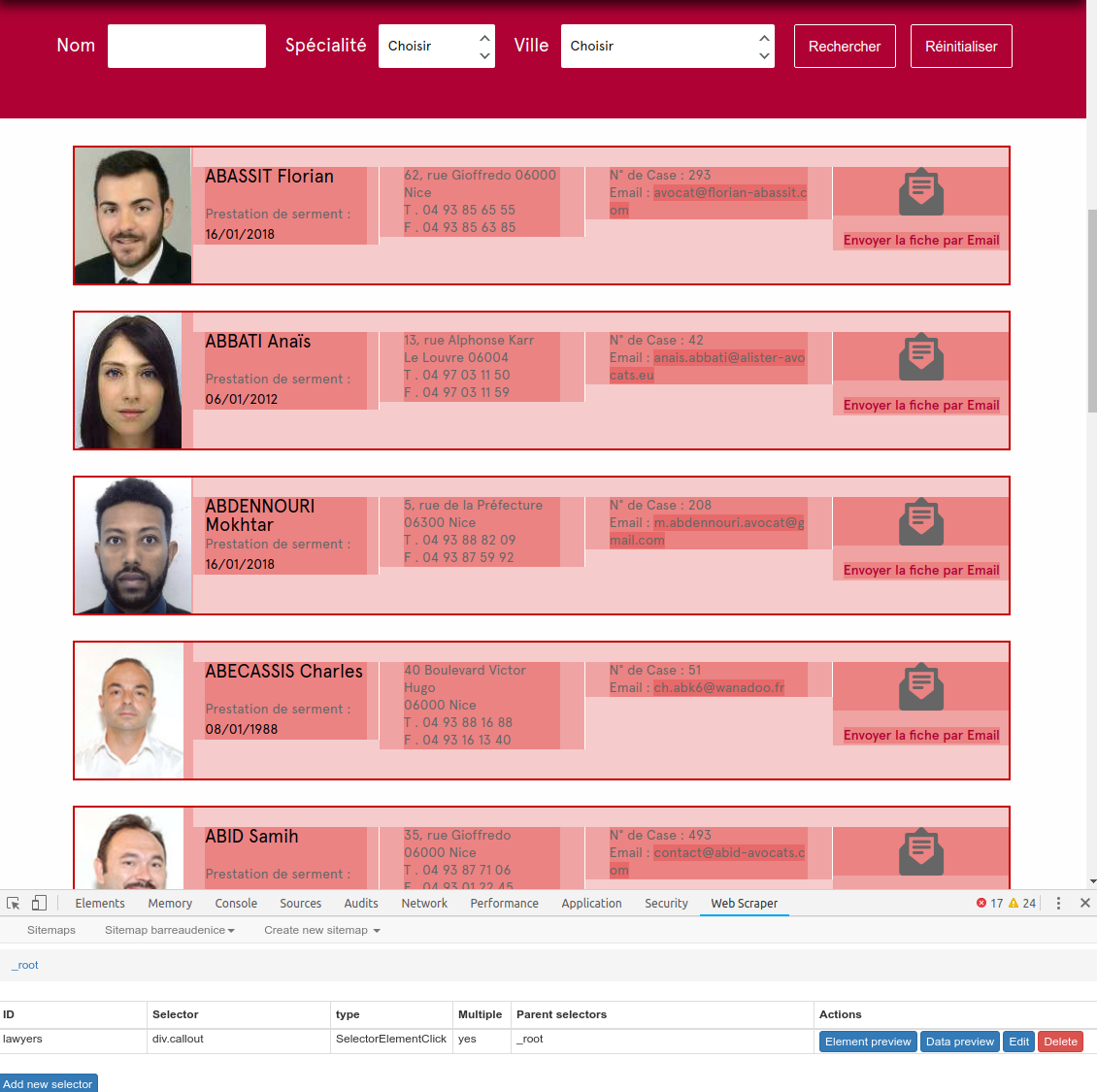
Le type « Element Selector » n’est pas fait pour indiquer un noeud HTML texte à extraire, mais il est utilisé pour grouper et cibler une même entité au sein de laquelle on va extraire plusieurs informations.
Par exemple, si il y a plusieurs lignes ou bloc avocats au sein d’une page, il faudra définir (ne pas faire attention au SelectorElementClick utilisé dans mon exemple):
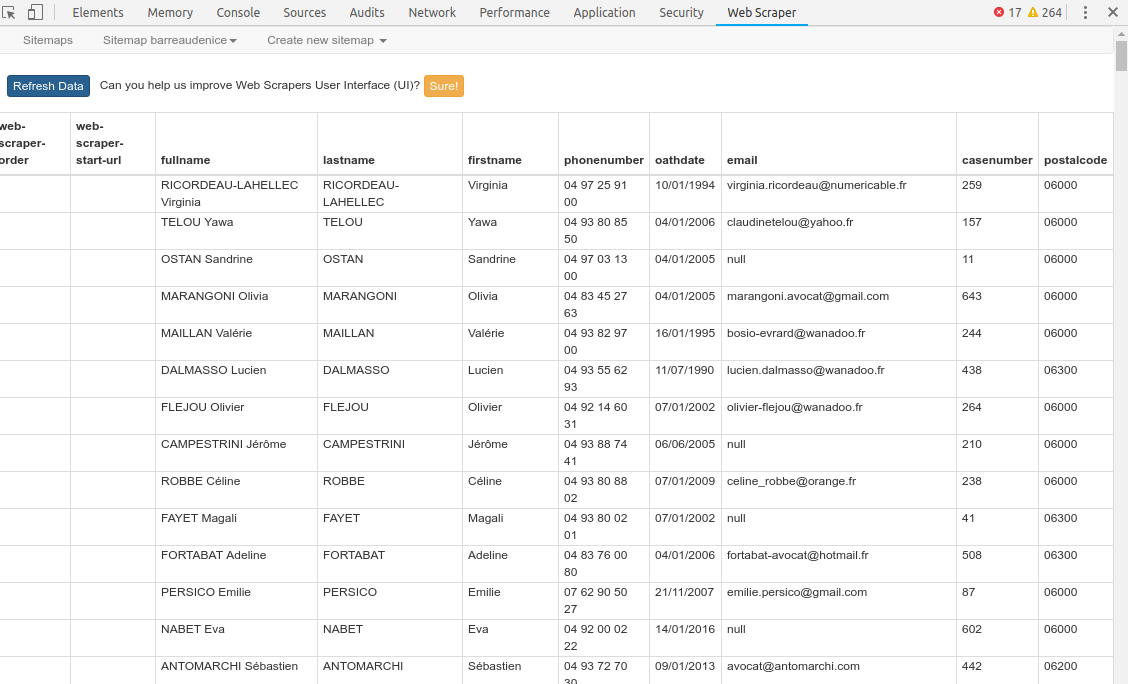
Et là dans cette deuxième étape, dans WebScraper il faudra descendre d’un niveau, et définir un sélecteur par champ de données à extraire, relativement au sélecteur parent.
De telle sorte qu’on puisse obtenir un tableau final (ou CSV) tel que:
OK, je n’avais pas envisagé cette possibilité, merci pour les explications, ça ouvre encore de belles possibilités ! Cet outil est vraiment sympa, et dire que je faisais tout en php avant