
7 « J'aime »
Est-ce que cest parce que les mecs de la team research de facebook on conçu une IA qui consomme moins en ressource que chatgpt que cela veux dire pour autant que il on détrôner chatgpt? LLAMA=chatgpt3 oui a peu de chose pres et on peux même le mettre en local moi jai essayer celui de 7B sur mon mac sa fonctionne bien mais chatgpt4>> LLAMA donc les mecs doivent encore upgrade cela
Le seul truc qui me fais dire que LLAMA est plus puissant que chatgpt3 c’est le fais que LLAMA ne possède pas de filtre comme gpt3 donc on peux facilement faire des scripts growth hack ou meme des malwares et ransomware sans a avoir des messages derreur comme chatgpt3 disant que cest contre éthique
Actuellement je suis entrain de composer un nouveau pc pour installer la derniere version LLAMA.cpp
2 « J'aime »
Les youtuber comme Micode et Hardisk font des super vidéos mais m’énervent avec leurs titres putaclics ^^.
Je rejoins @arkatacor34. Et plus il y aura de « concurrence » d’IA, mieux se sera (comme sur tous les marchés).
1 « J'aime »
Hello,
tu as deja eu le tps de tester llama ?
L’ouput a les meme contraintes que celles definies par openai ?
Je suis en ce moment même en train de tester llama car open ai bloque 1 fois sur 2 mes requêtes avec certaines pages HTML. Je vous ferai un retour!
3 « J'aime »
Non pas vraiment les filtres sur LLAMA ne sont pas assez present comme sur gpt3
Petit retour d’xp : ça tourne bien en local, plutôt incroyable d’avoir un like gpt sur son pc! J’ai utilisé la version 7B, et je retiens que c’est totalement débridé… L’IA t’accompagne dans toutes tes démarches… par ex il est capable d’aller crawler en direct le topic ici présent pour me faire un résumé.
4 « J'aime »
Je n’ai pas encore eu le temps d’essayer mais ton retour est vraiment intéressant ! Est-ce qu’il effectue lui-même le crawling ou génère-t-il le code nécessaire pour cela ? Ou bien est-ce que tu lui as montré comment utiliser un backend via un manifest, comme pour les plugins sur ChatGPT ?
Je ne sais pas du tout comment ça se passe, je n’ai pas eu accès aux logs lors de mes requêtes. Peut-être qu’il m’a donné une répones généraliste en prenant l’URL ou bien il a pu accéder à la page HTML du topic. A checker ![]()
2 « J'aime »
Ah d’accord, je comprends mieux. En fait, je pense qu’il t’a donné une réponse généraliste parce que, de base, ces modèles ne sont pas capables de crawler Internet par eux-mêmes. il faut leur montrer comment faire en leur montrant par exemple comment utiliser un backend qui crawl internet via une API et un manifest. C’est dans ce manifest qu’il faut indiquer au modèle comment utiliser ton API. C’est le principe utilisé dans les plugins ChatGPT. Je pense qu’il est totalement possible de l’implémenter sur llama. Si ça t’intéresse, voici la vidéo officielle d’OpenAI sur les plugins pour les dev https://openai.com/blog/chatgpt-plugins#chatgpt-plugins-developer-experience
1 « J'aime »
Ça, c’est énorme et c’est ce qui manque à GPT. Pour ça, que Google Bard peut tuer le game grâce à son gigantesque crawl quotidien. Et on comprend mieux le deal d’openai avec Microsoft. C’est pour pouvoir avoir accès au crawl de Bing.
Maintenant que le code est open source, la vraie différence viendra de celui qui apportera le plus de data à son IA.
Au final avec nos discussions sur le scraping, on était au cœur de l’avenir de l’IA sans le savoir ![]()
D’ailleurs je commence à me demander si Meta n’a pas utilisé Bright Data justement pour concevoir le dataset leaké en question :
3 « J'aime »
Le scraping ca rajoute une element super puissant a ce type d’outil, mais ca ralentit surement enormement le temps de reponse vs chatGPT
1 « J'aime »
C’est pour ça qu’il y a bcp de scraping sur le forum… On est à la pointe des tendances ici ![]()
1 « J'aime »
Quelqu’un a t’il trouvé une méthode pour faire que GPT aille crawler les pages d’un site web, avant de produire les réponses qu’on lui pose sur les informations présentes sur celui-ci ?
Les capacités de NLP de l’outil sont vraiment impressionnantes, mais aujourd’hui l’absence de crawl le conduit à répondre souvent à côté.
Exemple

en comparaison, quand on lui donne directement le contenu de la page du site:


1 « J'aime »
Bonjour à tous, sujet très intéressant. Je l’ai moi même installer sur deux Mac différents (un avec puce intel et un avec puce M1 Pro.) Il me semble que ça tourne largement mieux sur le M1 Pro. Par ailleurs, savez-vous comment faire pour le connecter à internet afin qu’il se source directement dessus ?
J’ai commencé un poc sur ce sujet justement, pour le moment ce n’est pas très mature mais je pense que d’ici 5-6mois on va avoir des solutions précises développées par la communauté pour réaliser ce tenre de tâche ![]()
1 « J'aime »
Je peux pas tester, c’est pas encore dispo sous Windows mais ça me semble intéressant,
Apparemment c’est en local et en non débridé, si qqn peut faire un REX ça serait cool, histoire de savoir si je m’impatiente pour rien ou pas ahah :
https://freedom-gpt2.netlify.app/
1 « J'aime »
C’est dispo sous windows !
@Dumpin, quand l’on clique sur Download for Windows !
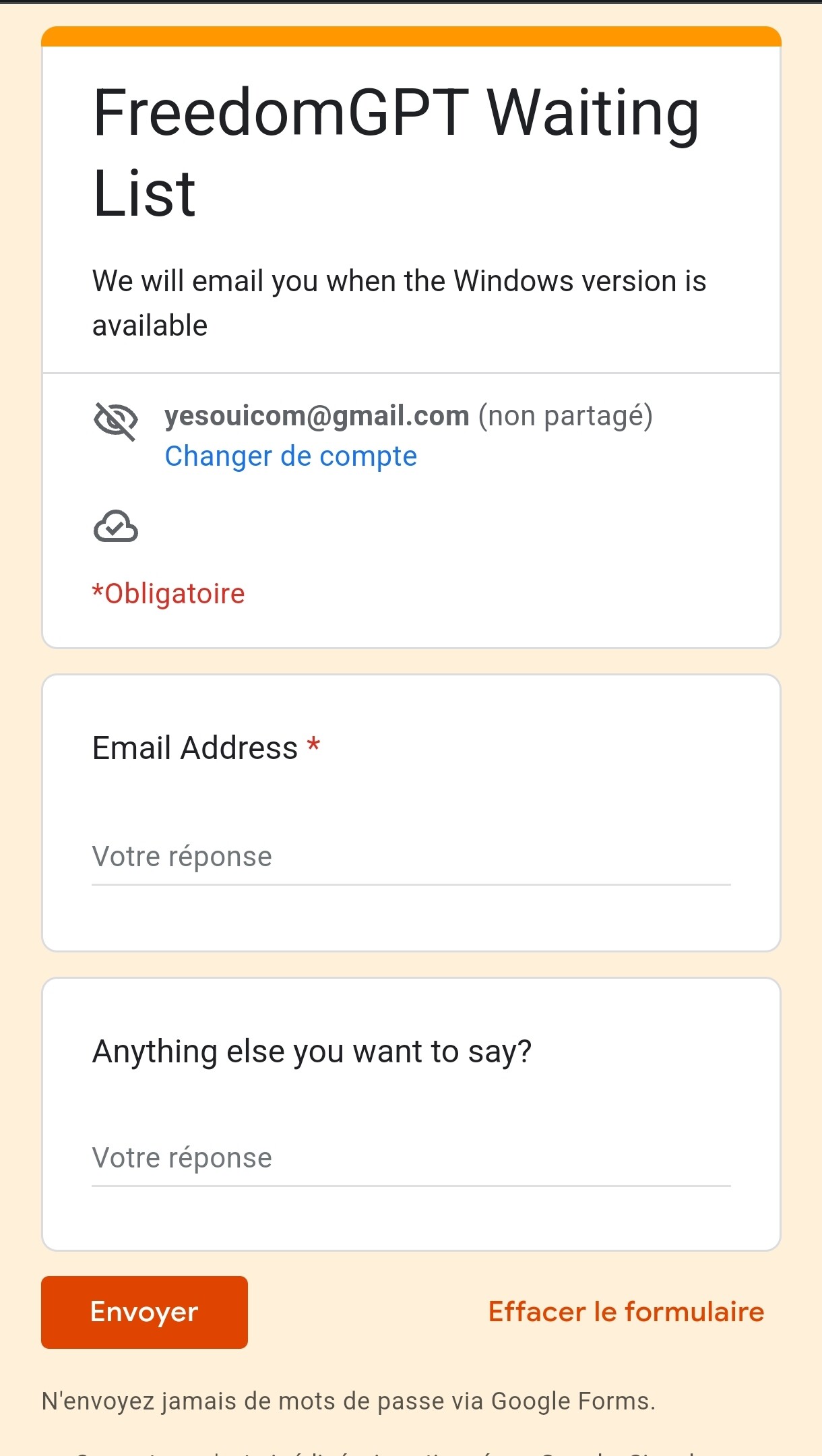
Alors que pour Mac y a bien le .dmg qui permet de l’installer
On a développé un scraper pour répondre justement à ce besoin, possible de le call via API. Plus d’infos en MP ![]()