Bonjour à tous,
Je viens vers vous pour un petit challenge que je rencontre actuellement : optimiser la méthode de récupération des emails des restaurants/bars parisiens référencés sur TripAdvisor.
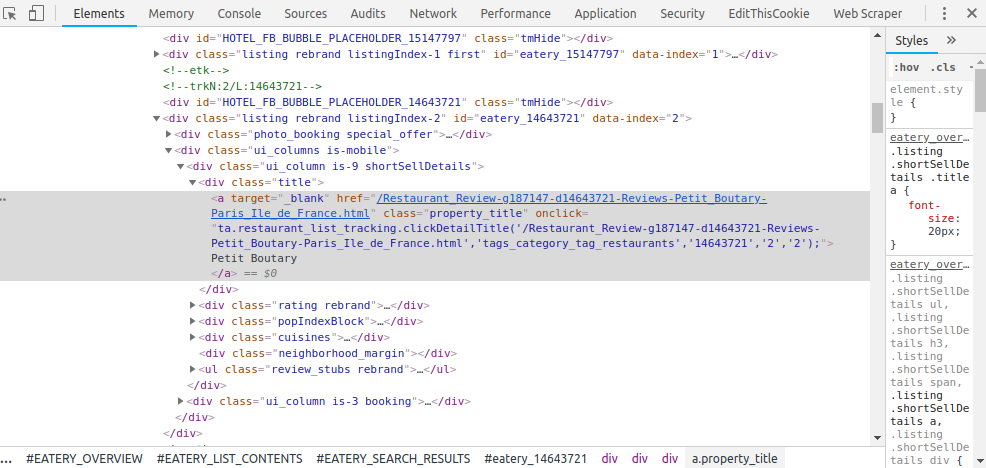
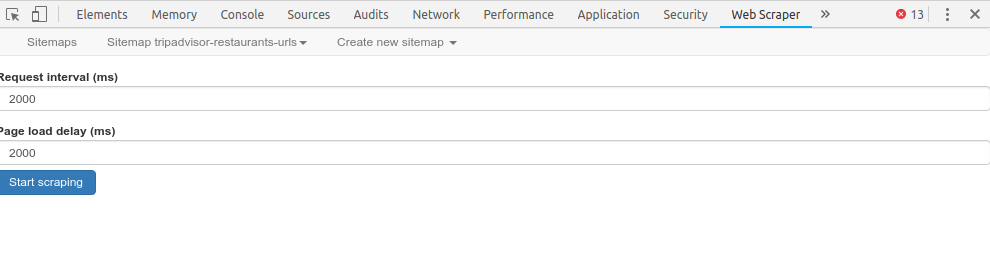
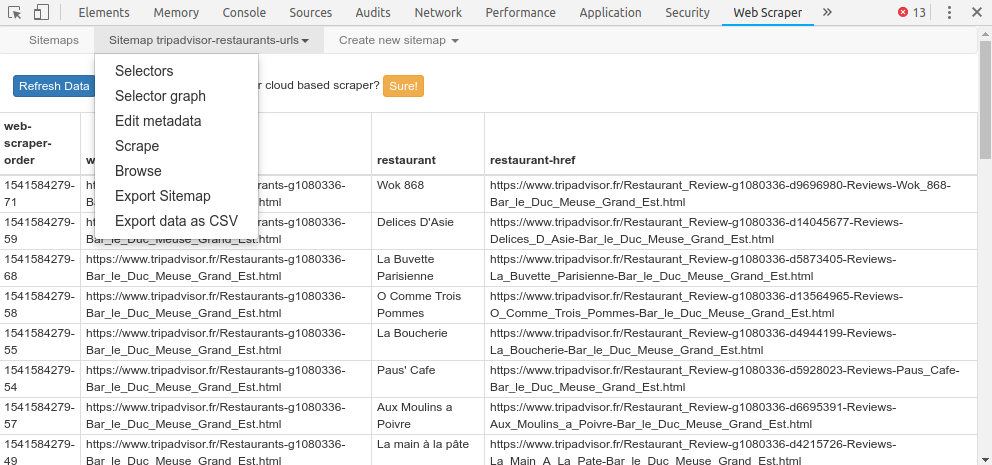
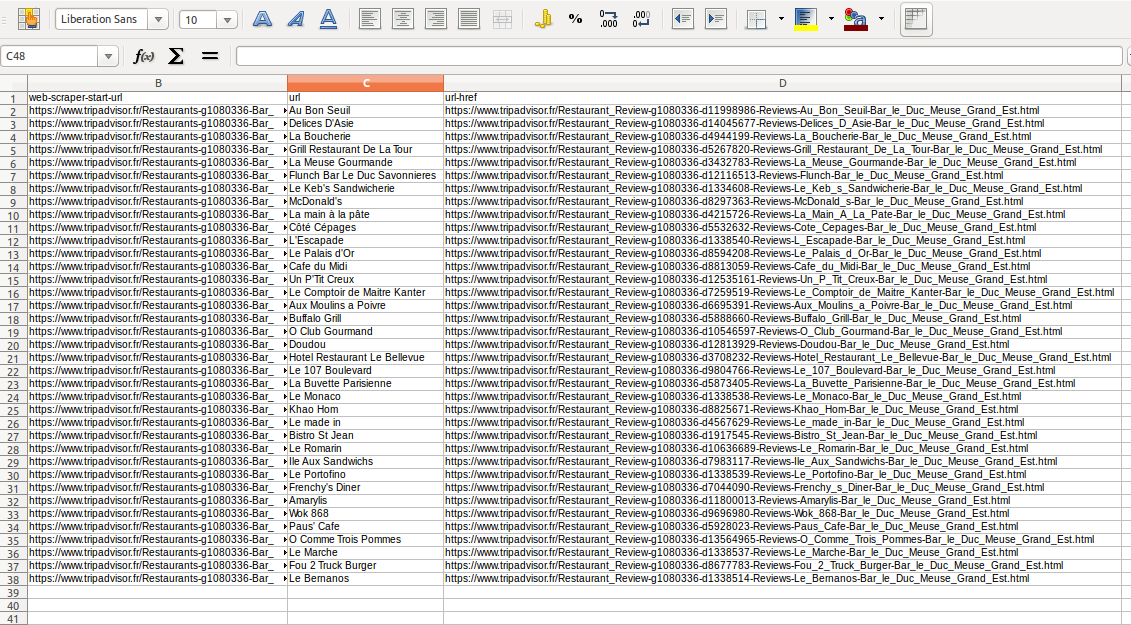
La première étape consiste à récupérer les URLs des pages de détail des établissement TripAdvisor, cette étape est celle qui me pose problème.
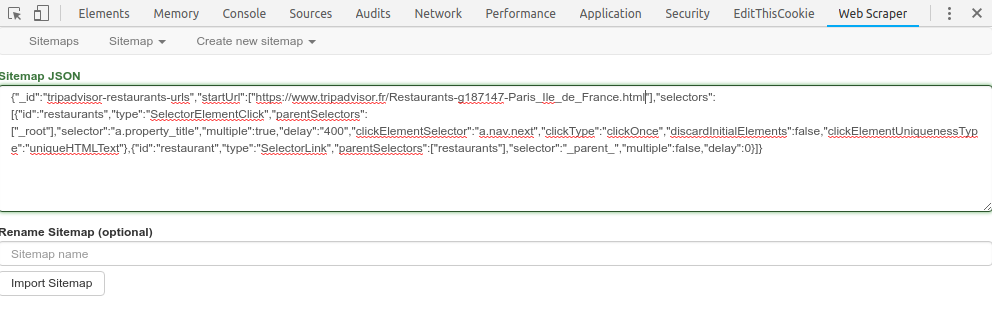
La seconde étape est de copier-coller les URLs récupérées dans ce superbe outil (développé par l’agence deux.io si je ne m’abuse) : http://spreadshare.webflow.io/spreadsheet/tripextractor
=> cette seconde étape fonctionne très bien.
Pour la première étape, j’ai tenté 2 méthodes :
Méthode 1 :
Scraping (avec extension, sans coder) des URLs des résultats Google pour une requête type : site:https://www.tripadvisor.fr inurl:Restaurant_Review « E-mail » « Paris »
=> Problème : les résultats Google Tripadvisor ne sont pas exaustifs par rapport à la liste de tous les établissements sur Tripadvisor (30 pages de 10 résultats Google, par rapport au 517 pages de 30 résultats. Autrement dit 300 établissements référencés sur Google contre 15,510 sur TripAdvisor.)
Méthode 2 :
Récupération des URLs directement via les pages de recherche TripAdvisor : LES 10 MEILLEURS restaurants à Paris - Mis à jour septembre 2024 (cliquer sur « Rechercher un restaurant » pour afficher la liste qui nous intéresse).
Donc là, soit on récupère les URLs à la main, ce qui évidemment trop long.
Soit, on récupère tous les liens via l’extension FF « Copy Links Advanced » > puis nettoyage des liens pollués via une macro réutilisable sur Excel avec une formule combinée « AutoFilter » + « EntireRow.Delete » /
=> problème : pas assez de points communs entre les URLs à supprimer pour faire une formule réellement efficace. Donc méthode pas concluante pour ma part. j’ai testé d’autres extensions mais rien de concluant pour le moment. J’ai également tenté de faire une recherche par CSS.selectors avec la même extension « Copy Links Advanced » mais pas concluant non plus.
L’un de vous aurait d’autres pistes pour récupérer les URLs de la page TripAdvisor ? (des changements dans la query Google ne marcheront pas car Google limite à 30 pages de résultats j’ai l’impression, sauf si vous avez une solution pour afficher plus de pages de résultats)
Merci si vous avez lu jusqu’ici,
Et merci d’avance de me venir en aide ![]()